Section 2: Assisting Classes
As opposed to a typical DSL architecture, where semantical checks, as well as model transformations, are seen as a part of the function library, PyNESTML implements a slightly different structuring of the components. In the previous section, checks for semantical correctness of a given model were already included in the model-processing frontend instead of characterizing this component as an element of the subsystem sitting between the frontend and the code generator. We, therefore, decided to factor out the functionality normally contained in the function library and instead delegate these components to the model-processing frontend and the generating backend. The result of the frontend should, therefore, be an AST representation of the model which has been checked for semantical and syntactical correctness. Moreover, model transformations are most often of target-platform specific nature, i.e., whenever several target platforms are implemented, it may be necessary to implement several model transformations. As illustrated in fig_mid_overview, it may be beneficial to regard model transformations as a part of the target-format generating backend and encapsulate all components required for a specific target in a single subsystem. Following these principles, the overall PyNESTML architecture has been implemented in the following way: A rich and powerful frontend is followed by a small collection of workflow governing and assisting components, which are in turn concluded by several, independent code generators. In this section, we will introduce components sitting in between and governing the overall model-processing control flow and providing assisting functionality. Although not crucial, these elements are often required to provide a straightforward tooling as well as certain quality standards.
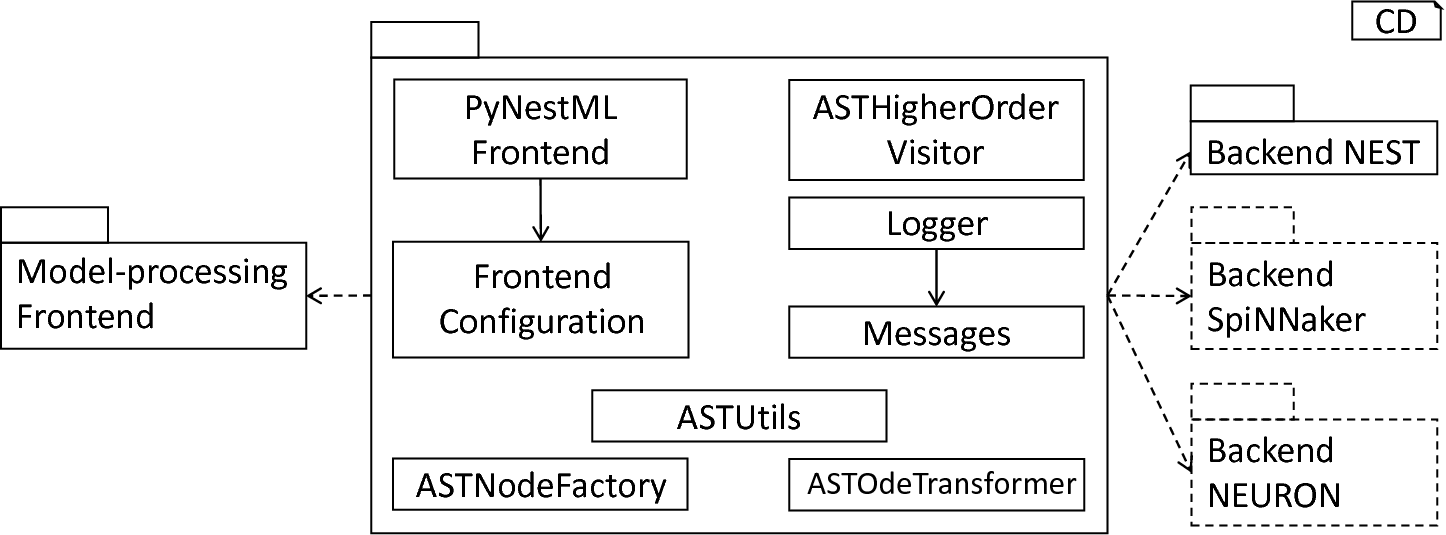
Overview of assisting components: The PyNESTMLFrontend represents an orchestrating component, governing PyNESTML’s workflow. Parameters handed over by the user are stored in the FrontendConfiguration, while the Logger and Messages classes take care of logging. For the modification and creation of ASTs, the ASTUtils, ASTNodeFactory and ASTOdeTransformer are employed. The ASTHigherOrderVisitor represents an assisting component making traversal and modification of ASTs easier.
As introduced in the previous section, the ModelParser class reads in and checks a textual model for syntactical and semantical correctness. However, transforming the model to an equivalent AST is only the first step in the overall processing. The introduction showed which other steps have to follow and therefore to be chained and governed by an orchestrating component. This task is handled by the PyNESTMLFrontend class, a component which represents the workflow execution unit and hides the model transforming process behind a clearly defined interface.
Before the actual processing of the model can be started, it is necessary to handle all parameters as handed over by the user, e.g., the path to the models. These parameters tend to change frequently whenever new concepts and specifications are added. PyNESTML, therefore, delegates the task of arguments handling to the FrontendConfiguration class. By utilizing the standard functionality of Python’s argparse [1] module, the frontend configuration is able to declare which arguments the overall system accepts. The handed over parameters are stored in respective attributes and can be retrieved by the corresponding data access operations. All attributes and operations are hereby static (class properties) and can be accessed from the overall framework by simply interacting with the class. Whenever new parameters have to be implemented, it is only necessary to extend the existing FrontendConfiguration class with a new attribute and access operation, while the remaining framework remains untouched.
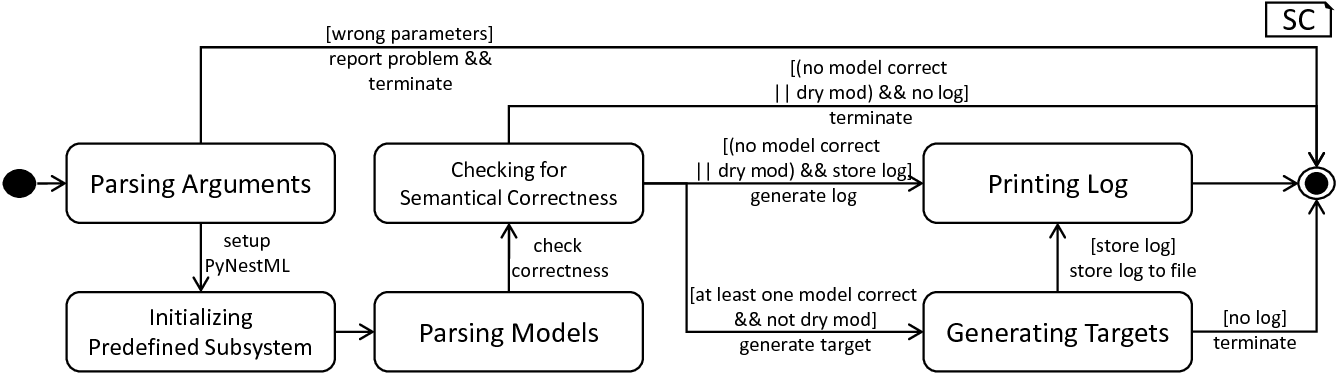
The model-processing routine as orchestrated by the PyNESTMLFrontend
All arguments as handed over to the PyNESTMLFrontend class are therefore first delegated to the FrontendConfiguration class where all settings are parsed. Only if a valid set of arguments is available, the system proceeds. First, the predefined subsystem of the previous section is initialized. Subsequently, the ModelParser class and its parseModel method are used to parse the model. This process is executed for all handed over artifacts, with the result being a collection of neuron models represented by ASTs. After all models have been parsed, it remains to check a context condition which is only available whenever several artifacts are processed, namely CoCoNoTwoNeuronsInSetOfCompilationUnits. PyNESTML checks in the list of all processed artifacts whether two neurons with equal names are present. Although not directly semantically incorrect, this property still has to be ensured. Otherwise, a generated C++ implementation of the respective neuron would overwrite a different one, leading to unexpected results. The corresponding context condition is hereby directly invoked on the CoCosManager. All errors are reported and logged by means of the Logger class. If the developer mode is off, PyNESTML inspects the log and removes all neurons from the current collection which have at least one found error. The adjusted collection is then handed over to the code generating backend. After all models have been processed, the overall log is inspected and stored in a file if required. In conclusion, the PyNESTMLFrontend class represents the overall workflow execution unit, and combines the model-processing frontend and the code-generating backend. fig_model_processing_routine subsumes the presented procedure.
The Logger represents an assisting class which is used in almost all parts of the PyNESTML framework. Errors during the parsing and semantical checks as well as all complications arising in the code generators are reported by means of this component. Often identical errors can occur in several parts of the toolchain, e.g., an underivable type in the expression and data-type processing visitors. Whenever these messages have to be adjusted, it is necessary to locate all occurrences and adjust equally in order to preserve consistency. The implementation tackles this problem by storing all messages in a single unit, namely the Messages class as shown in fig_logger_messages. Each message is encapsulated in a private field and can not be directly accessed. Instead, a corresponding getter is used. Consequently, all messages can be changed while the interface remains unaffected. Moreover, the Messages class implements an additional feature which makes specific filtering of messages easier to achieve. In order to avoid direct interactions with message strings, each message is returned as a tuple consisting of a string and the corresponding message code. The message code is hereby an element of the MessageCode enumeration type which provides a wide range of message and error codes. Whenever a getter method of the Message class is invoked, a tuple of a message and the corresponding code is returned. Each reported issue can, therefore, be identified by its error code, making filtering of messages by their type or logging level possible.
The Message class makes reporting of errors easy to achieve and maintain. The actual printing and storing of reported issues is delegated to the Logger class, where all messages are stored together with several qualifying characteristics. In order to filter out messages which are not relevant according to the user, a logging level can be set. Messages whose logging level is beneath the stored one are not printed to the screen but may be stored in the optionally generated log file. In order to associate a message with its origin, i.e., the neuron model where the corresponding error occurred, a reference to the currently processed neuron is stored. All messages can therefore also be filtered by their origin.
The corresponding set of operations on the logger represents a complete interface for the storing, printing and filtering of messages. The logMessage method inserts a new message into the log and expects the above-mentioned tuple. The getAllMessagesOfLevel method returns all messages of a specified logging level, while getAllMessagesOfNeuron returns all issues reported for a specific neuron model. The hasErrors method checks whether a neuron does or does not contain errors. The final operation of this class is the printToJSON method. As introduced in the PyNESTMLFrontend class, it is possible to store the overall log in a single file. For this purpose, first, it is necessary to create a sufficient representation of the log in JSON format. This task is handed over to the aforementioned method, which inspects the log and returns a corresponding JSON string representation. In conclusion, all methods of this class represent an ideal interface for a troubleshooting and monitoring of textual models.
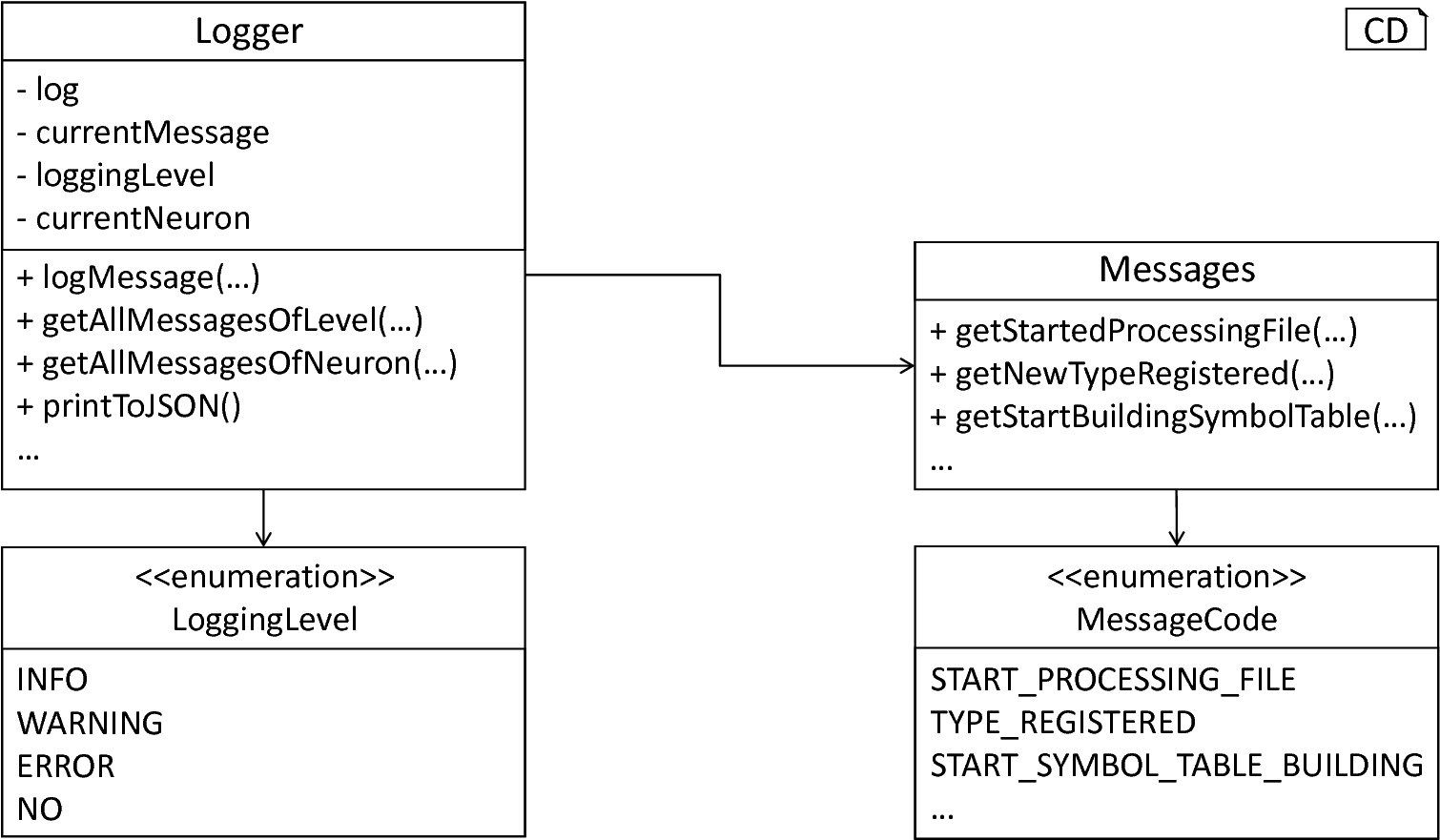
The logger and messages components: The Logger provides methods for reporting issues (logMessage) and precise retrieval of messages (e.g., getAllMessagesOfLevel). For a log in file format, the printToJson method can be used. In order to make maintenance more focused, all message strings are encapsulated in the Messages class. The currently set logging level, as well as individual message codes, are hereby of an enumeration type.
The ASTNodeFactory class implements the factory pattern [2]and provides a set of methods used to initialize new AST nodes, while the ASTUtils class represents a rather broad collection of operations required across the overall framework. In the case of the latter, especially two methods are of interest: The isCastableTo method returns whether a type X can be cast to a type Y, ensuring that the types of both sides of a given declaration or assignment in the model are equal or at least castable into each other. The differsInMagnitude method, on the other hand, returns whether two types represent the same physical unit and only differ in the magnitude. As introduced in Section 1: The model-processing Frontend, both operations are required to ensure that models are regarded as being correct although containing minor typing differences.
Transformations which are especially focused on the equations block and its definition of differential equations are contained in the ASTOdeTransformer class. Although solely used by transformations contained in the code-generating backend, this class has been decoupled and represents a self-contained unit. Independently of the concrete target platform for code generation, it is often necessary to modify all ODEs in a given model. This class provides a collection of operations for the data retrieval from and manipulation of ODEs. The getter functions collect function calls contained in all declared ODEs. The corresponding manipulation operations are marked by the prefix replace and can be used to replace certain parts of an ODE by other specifications. Although these operations could also be included in the ASTUtils class given their nature of manipulating an AST, for a clearer separation of concerns all operations on the ODE block have been delegated to a single unit. As we will demonstrate in Section 3: The Generating Backend, it is often necessary to adjust a given equations block and transform a set of expressions. By encapsulating all operations in a unit, a clear single responsibility and therefore maintainability is achieved. fig_ast_manipulating summarizes the provided functionality of the ASTOdeTransformer.

AST-manipulating modules: The ASTOdeTransformer implements a set of operations focused on the retrieval of information from and modifications of the ODE block. The ASTNodeFactory offers operations for the creation of AST nodes, while ASTUtils contains a vast collection of operations on the AST.
We conclude this section by an introduction of the higher-order visitor, a concept which has been implemented to reduce the amount of code and effort required to interact and modify a given AST. Although highly applicable, this approach can only be employed in programming languages where functions and operations are regarded as objects and can, therefore, be handed over as parameters to other functions. Luckily, this applies to Python and its concept of duck-typing.
Section 1: The model-processing Frontend and especially its semantical checks illustrated that it is often necessary to perform a set of operations on certain types of nodes in a given AST, e.g., whenever all function calls with a specific name and arguments have to be collected. The visitor pattern [3] provides a possible approach for an implementation of such procedures, where concrete operations and the visiting order are decoupled. If one or the other routine has to be modified, the user can simply override the corresponding operation. However, visitors which implement simple operations still require an extension of the base class, making the hierarchy of classes less comprehensible and cluttered. Moreover, in the case that two visitors have to be combined to a single one, it is not directly possible to mix them, but required to implement a new visitor containing both. All this leads to a situation, where maintenance of components is not focused, but distributed over a hierarchy of visitors and their assisting operations, blowing up the code base with unnecessary code and repetitive definitions of new classes.
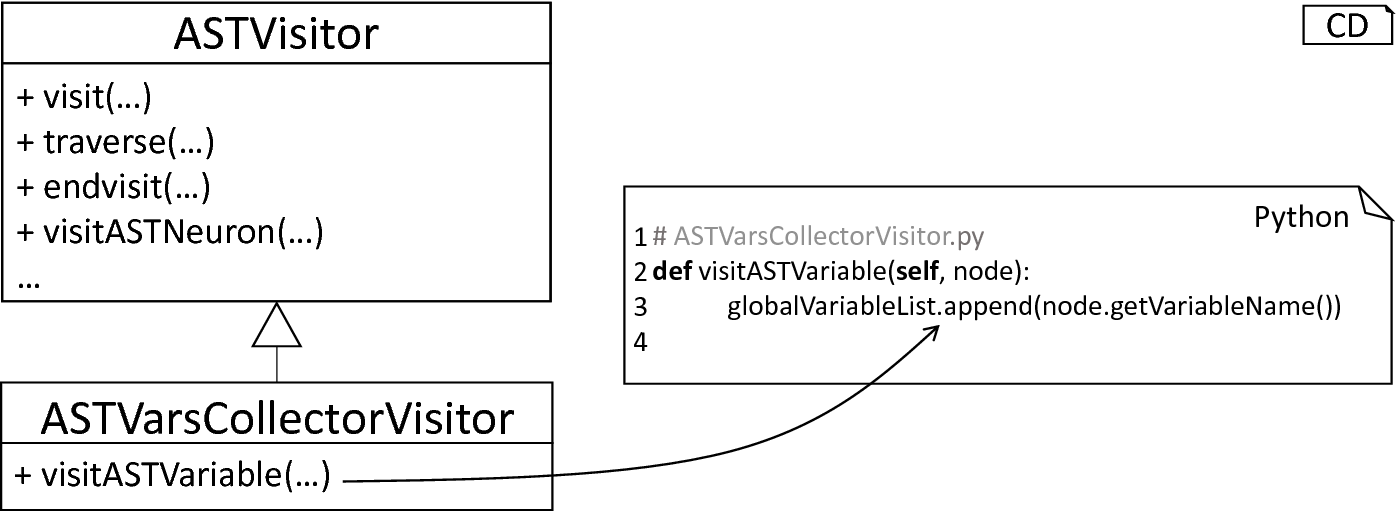
The visitor pattern in practice: Even small operations, e.g., the collection of certain types of variables, require the usage of sub-classing, where only a single operation is redefined.
Especially in the case of PyNESTML and its semantics-checking subsystem many visitors had to be written. In order to avoid the above-mentioned problems, the concept of the higher-order visitor was developed. Analogously to the (generated) base visitor, this class implements a traversal routine on the AST. However, instead of overriding the base visitor and providing all operations on the AST in a new class, it is only required to hand over a reference to the operation which should be performed on the AST. Coming back to the introductory example: Here, it is only necessary to check whether a node represents a function call, and which arguments it has. Both operations can be stored in a single function definition. The higher-order visitor, therefore, expects such a function reference, traverses the AST and invokes the operation on each node. Other modifications, e.g., which visit a node twice or simply skip it, are directly encapsulated in the corresponding function. Utilizing this concept, many obstacles can be eliminated. Simple visitors, e.g., those collecting all variables in a certain block, can be implemented in-place as illustrated in fig_higher_order_visitor. The overall code base becomes smaller, while visitors are defined together with their caller, making maintenance easy to achieve and data encapsulation a built-in property.
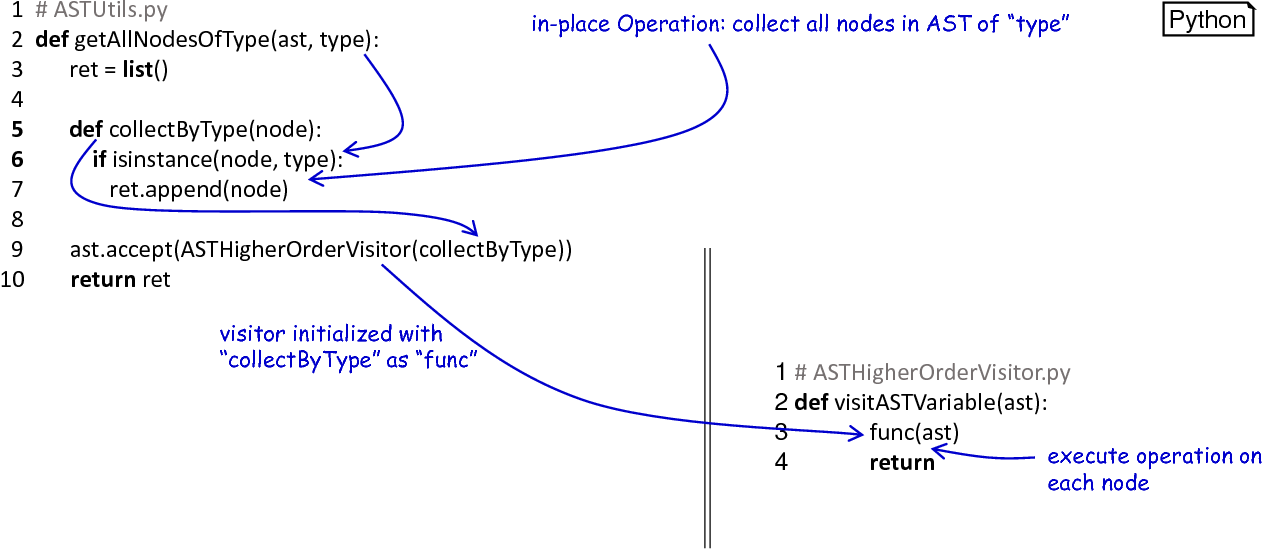
The Higher-Order Visitor: The visit operation is provided by the AST whose subtree shall be visited and the actual operation. This operation can be either declared in-place by lambda expressions or as a reference to a different function. The higher-order visitor traverses the tree and invokes the function on each node.
In this section, we presented all assisting classes as contained in the framework:
FrontendConfiguration: A configuration class used to store handed over parameters.
PyNESTMLFrontend: A class providing a simple interface to PyNESTML.
Logger and Messages: A logger with a set of corresponding messages for precise and easy to filter logs.
ASTNodeFactory and ASTUtils: Collections of assisting operations as used to create and modify ASTs.
ASTOdeTransformer: A component specialized in manipulating ODE blocks.
ASTHigherOrderVisitor: A visitor which expects a function, which is then executed on each node in the AST. Makes inheritance for simple visitors no longer necessary.
All these components make PyNESTML easier to maintain and ensure basic qualities of a software, namely data abstraction, separation of concerns and single responsibility. As we will see in Section 4: Extending PyNESTML, all these characteristics are highly anticipated and make integration of extensions an easy to achieve goal.