Section 3: The Generating Backend
The generation of executable code is one of the most important aspects of a DSL-processing framework and enables the validation of the modeled concepts. The transformation of a textual model to an executable representation by means of a DSL framework prevents a manual, error-prone mapping of models to target platforms. In the case of PyNESTML, the NEST simulator [1] was selected as the first major platform for code generation. NEST represents a powerful simulation environment for biological neural networks and is implemented in C++. In this section, we will demonstrate how the code-generating backend was implemented to generate NEST-specific C++ code. For this purpose, Section 3.1 will first introduce the orchestrating NestCodeGenerator class and subsequently demonstrate how models are adjusted to be more NEST affine. An overview of the components used to generate NEST-specific code subsequently concludes this section. fig_overview_backend illustrates the subsystems as introduced in the following and their relations.
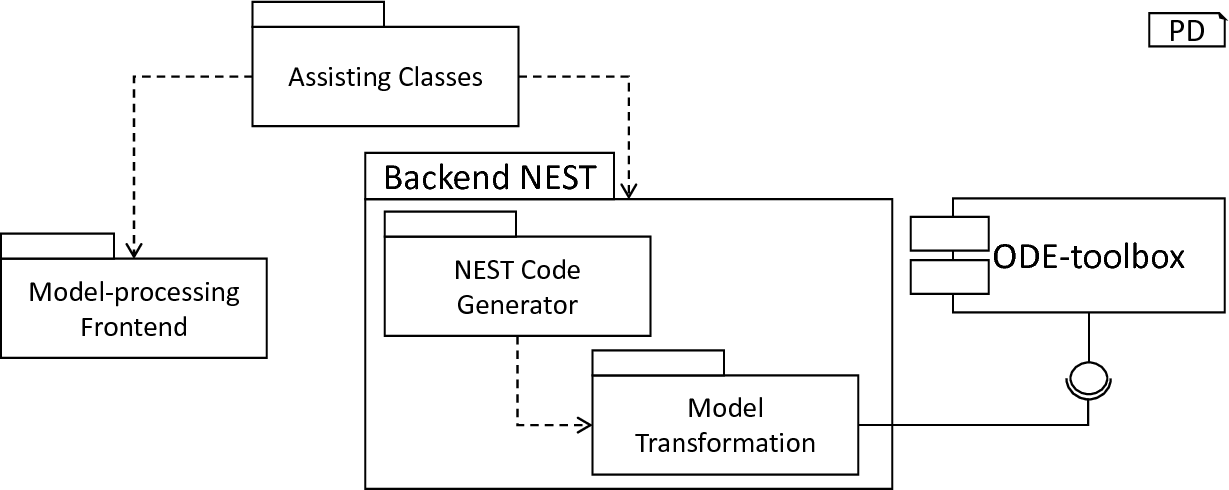
Overview of the code-generating backend: The model-processing frontend provides an input AST for the code generation. The NEST-specific backend first transforms the AST by means of the model transformation subsystem, before the NEST code generator is used to generate the respective C++ code. The instructions how the AST has to be adapted are computed by an external ODE-toolbox.
Section 3.1: AST Transformations and Code Generation
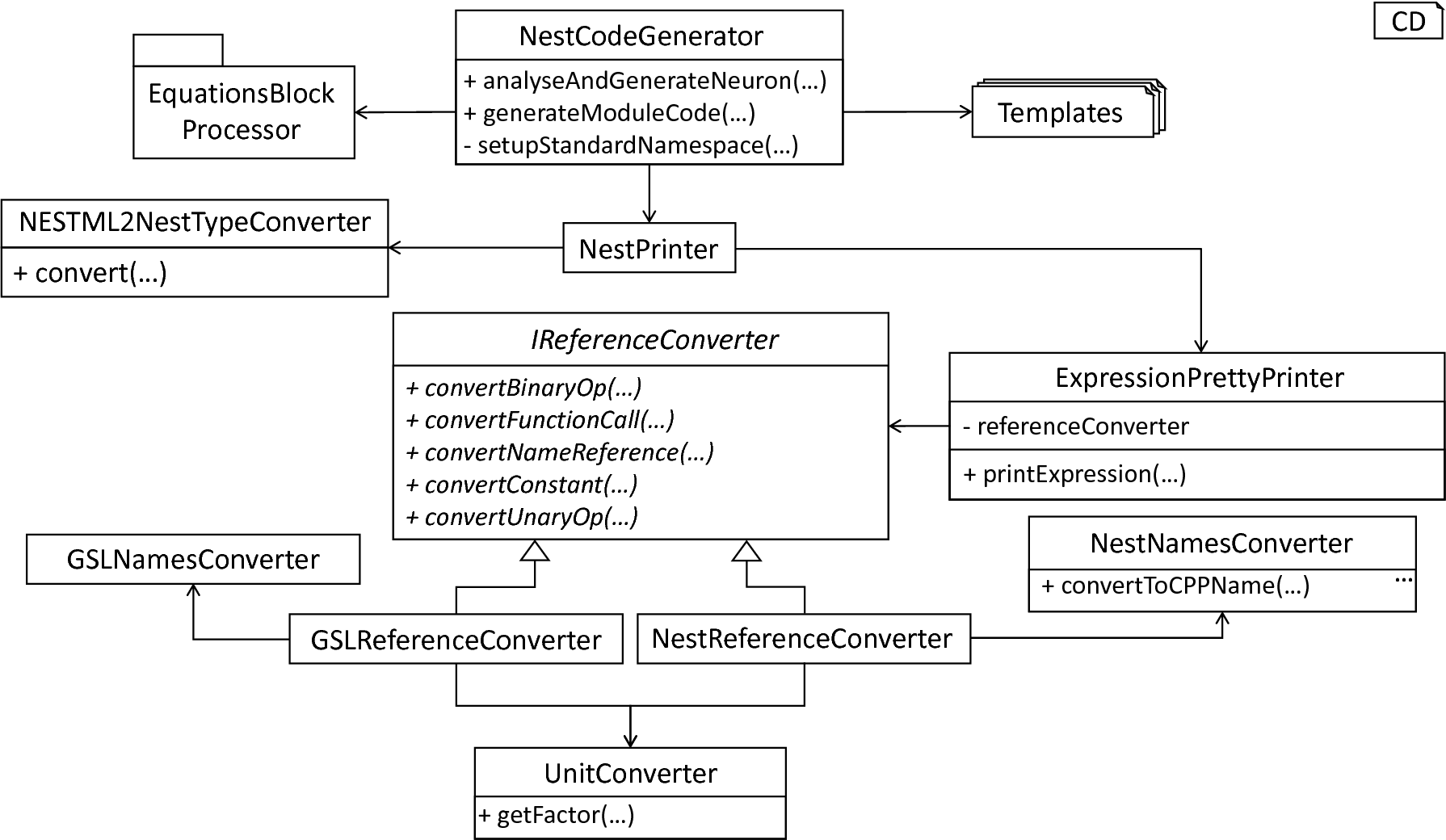
Overview of the NEST code generator.
In order to demonstrate the code-generating backend, this section will first introduce the coordinating NestCodeGenerator class and show how the code generation is prepared by transforming the handed over AST to a more efficient form. Subsequently, we highlight a set of templates used for the generation of NEST-specific C++ code. Concluding, an introduction to the special case of expression handling as implemented in the ExpressionPrinter class is given. fig_overview_nest_code_generator illustrates all components of the code-generating backend.
The NestCodeGenerator class orchestrates all steps required to generate NEST-specific artifacts. The overall interface of this class consists of the analyseAndGenerateNeuron and generateModuleCode methods. By separating the code generation into two different operations, a clear single responsibility is achieved. While all steps necessary to generate the C++ implementation of a neuron model are executed in the analyseAndGenerateNeuron method, the task of generating a set of setup artifacts is delegated to the generateModuleCode method. The analyseAndGenerateNeuron function hereby implements the following steps: First, the assisting solveOdesAndKernels function is executed which indicates whether a transformation of the model to a more efficient structure is possible. If so, the AST is handed over to the further-on presented EquationsBlockProcessor class, and a restructured AST is computed. Back to the orchestrating analyseAndGenerateNeuron method, an update of the symbol table is invoked by means of the ASTSymbolTableVisitor, cf. Section 1: The model-processing Frontend. This step is required in order to update the model’s symbols according to the restructured AST where new declarations have been added. Finally, the generation of C++ code is started by means of the generateModelCode method. Being responsible for the generation of a header as well as an implementation file of a concrete neuron model, this operation delegates the work to the generateModelHeader and generateModelImplementation subroutines. fig_processing_model_nest_backend summarizes the above-introduced workflow.

Processing of a model in the NEST backend.
Depending on the selected simulator or environment, different concepts may be supported. This circumstance has to be regarded whenever code is generated. While simulation environments such as LEMS [2] support physical units as an integral part of the simulation, others such as NEST do not. In order to avoid unsupported declarations of models, an AST-to-AST transformation is implemented which restructures the source model to a target platform supported format. Besides missing support for certain concepts, also an optimization of declared models is often of interest. Transformations, therefore, enable a DSL framework to adjust models to specific targets and generate efficient code.
In the case of PyNESTML, all transformations of neuron models are focused on the equations block, where, depending on the stated declarations, models are restructured and definitions transformed to a more efficient and easy to generate form. The target simulation environment NEST utilizes the GNU Scientific Library (GSL [3]) for the evaluation and integration of differential equations. GLS expects a special form of the equations block where only ordinary differential equations (ODEs) with their respective starting values have been declared. Such a form enables an efficient computation and handling of neuron spikes. For models which contain declared kernels it is, therefore, necessary to compute an exact solution where the equations block evolution is replaced by direct computation steps. In cases where such an optimization is not possible, at least a transformation of all kernels to equivalent representations by means of ODEs and initial values shall be computed. Such a form of the neuron model avoids time-consuming evaluation of kernels for each time-step t. To summarize, the first major task of the code generator is to perform an AST-to-AST transformation where the equations block is replaced by an exact solution or all kernels have been converted to ODEs and initial values. All this helps to normalize the generated code and therefore to ease its evaluation.
In order to compute these optimizations, the ODE-toolbox as introduced by Blundell et al. [4] is integrated. Written in Python, the ODE-toolbox can be used in a black-box manner to restructure a stated equations block to a less computationally expensive form. Amongst others, it features concepts for a derivation of exact solutions, elimination of computationally expensive kernels, and constants folding. For an interaction with this tool, it is first necessary to convert the equations block to a representation processable by the ODE-toolbox, and subsequently, integrate the computed new formulation of the ODE or an exact solution into the source AST. The referenced ODE-toolbox is implemented in an environment-agnostic manner, where an exchange of data with the toolbox is performed over the platform-independent JSON [5] format. Before the ODE-toolbox can be used, it is therefore first necessary to create a representation of a model’s properties in JSON format. Such a handling makes the used ODE-toolbox an exchangeable component, where only the wrapper converting and exchanging data has to be adjusted whenever a different toolbox is used. PyNESTML delegates the interaction with the toolbox to the SymPySolver class. Summarizing, the overall process as employed in this component can be described as follows: Given an equations block, print its specifications to an equivalent JSON string. Hand over the generated JSON object to the ODE-toolbox and finally invoke the optimizing routine. Afterward, the computed results are integrated into the AST by the EquationsBlockProcessor class and its assisting components. fig_model_transformation_subsystem illustrates the AST-transforming part of the NEST code generator.
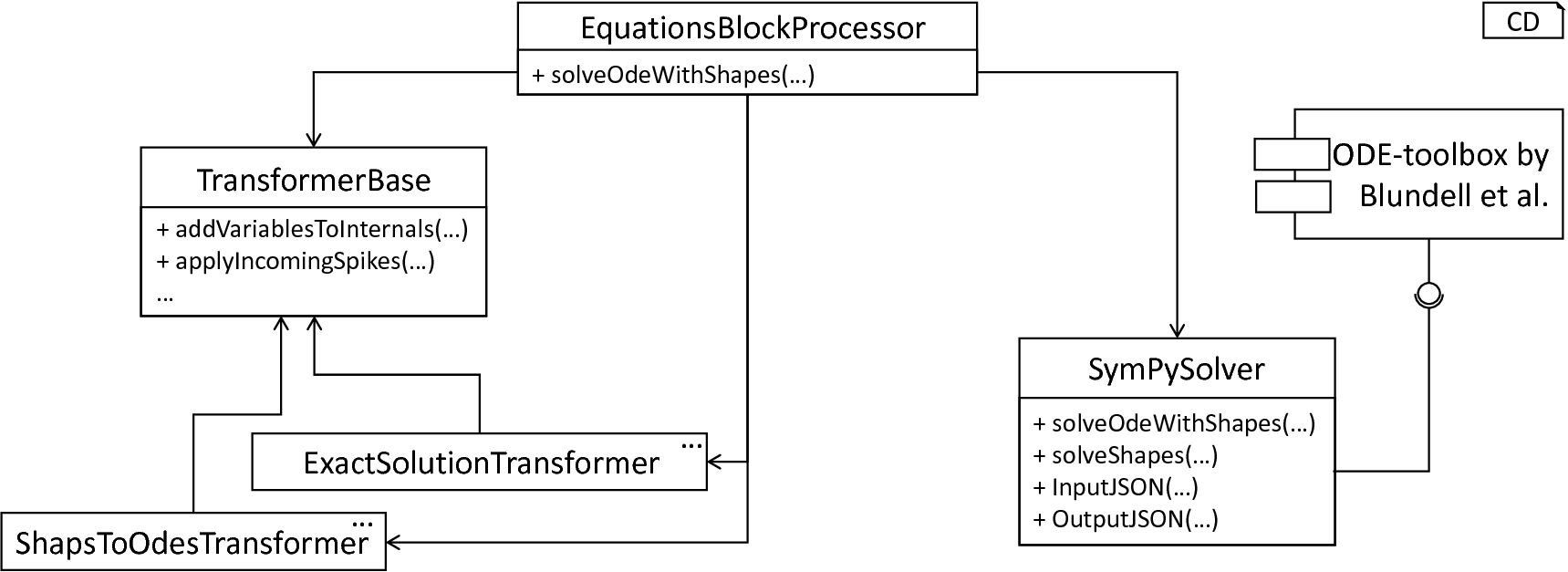
The model transformation subsystem: The EquationsBlockProcessor receives a neuron model. The equations block is extracted and handed over to the ODE-toolbox by means of the SymPySolver wrapper class. The returned result is finally processed by the transformers and integrated into the AST.
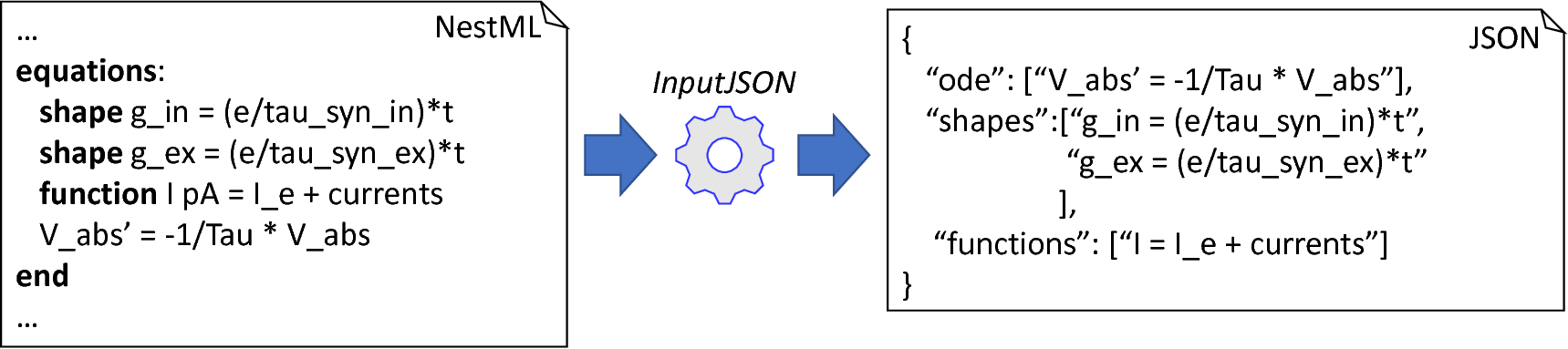
From NESTML to JSON: In order to interact with the ODE-toolbox, all declarations contained in the equations block are converted to JSON format.
The task of creating a JSON representation of a given equations block is handled by the InputJSON method. The purpose of this operation is to analyze the equations block, print all components to a processable format and finally restructure it into a correct JSON string. This function retrieves three different types of equation specifications as definable in the equations block, namely all kernels, functions and equations. Instead of handing over an AST to the ODE-toolbox, all expressions are first printed by means of the ExpressionPrinter class to a Python-processable format. By exchanging strings instead of objects, a better control and comprehension of all side effects is achieved. For all three types of declarations in the equations block, PyNESTML implements an additional printing routine: The printEquation function retrieves the name of the left-hand side variable together with the differential order and combines it with the right-hand side expression printed by the ExpressionPrinter. This procedure is executed analogously for kernels and functions. Finally, it remains to combine the stored strings to a valid JSON format. The InputJSON function, therefore, iterates over the stored strings and combines them by means of a correct syntax as illustrated in fig_nestml_to_json. The result of the process as implemented in this function is a JSON string encapsulating all equations block specifications in a format processable by the ODE-toolbox.

Interaction with the ODE-toolbox: Stated declarations in the source model are transformed to an equivalent representation in JSON format and handed over to the ODE-toolbox. The computed modifications are de-constructed from JSON format to a collection of individual definitions and integrated into the model.
Having a representation of the equations block in an appropriate string format, PyNESTML starts to interact with the ODE-toolbox. The concrete communication is hereby delegated to the orchestrating SymPySolver class. This component represents a wrapper for the ODE-toolbox and executes all steps as required to communicate with the toolbox and convert the input and output to appropriate formats, cf. fig_interaction_ode_toolbox. The input format is hereby encapsulated in a JSON string as constructed by the InputJSON function, which is subsequently handed over to the compute-solution operation of the ODE-toolbox. The result of this operation is a set of modified declarations where certain parts have been replaced or simplified, e.g., kernels represented by ODEs and initial values. Analogously to the input, the output as returned by the toolbox is also represented by means of a string in JSON format. It is, therefore, necessary to parse the modified declarations and inject them into the currently processed AST. In order to make the overall processing modular and easy to maintain, PyNESTML implements the OutputJSON function which is solely used to de-construct a JSON string to a collection of individual elements. The actual processing and injection of computed ODE declarations into ASTs is delegated to the TransformerBase and its assisting classes.
The OutputJSON function returns a dictionary of fields for different declarations as computed by the ODE-toolbox. All fields store the modified ODE declarations as a string, while the actual parsing is executed by subsequent components. The status field, for instance, indicates whether any problems occurred during the equations block processing. The remaining fields analogously define other properties which can be added by the ODE-toolbox, e.g., new state variables and differential equations. The decomposed output as stored in the dictionary can now be used to perform an AST-to-AST transformation.
Having an optimized structure of the equations block, PyNESTML starts to transform the AST. Here, depending on the type of the returned solution, a different handling is required. However, which handling is concretely executed should not be a concern of PyNESTML, but rather selected according to the toolbox output. This routine is therefore implemented in the EquationsBlockProcessor class which encapsulates all steps of the transformation in a single method. Consequently, whenever it is required to analyze a given model and transform it according to the computed modifications, the functionality as contained in this class is used. The underlying processing is hidden and therefore easy to exchange and maintain.
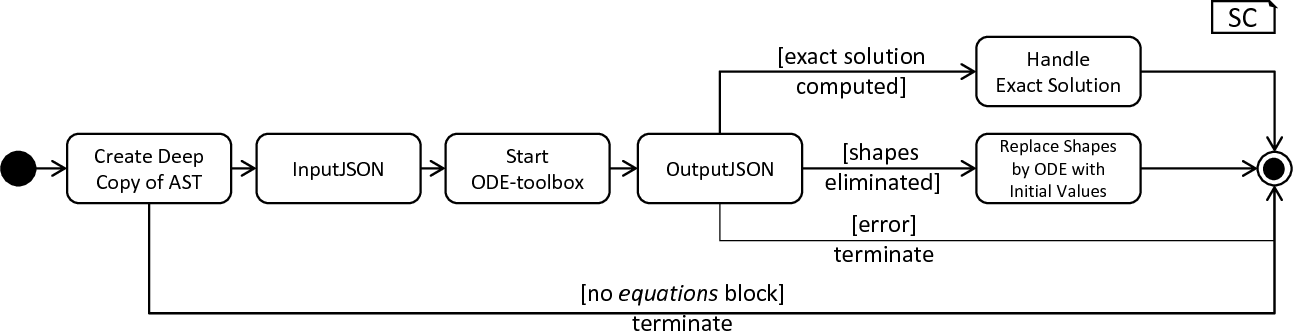
The model-transforming process.
The transformation of a neuron model can be invoked by means of the solveOdeWithKernels method of the EquationsBlockProcessor. This operation expects a single neuron model and performs a series of steps as illustrated in fig_model_transforming_process. First, a new deep copy of the processed AST is created. Potentially having several targets for code generation with individual transformations, each backend transformation should work on a local copy instead of modifying a global one. Without creating a local working copy, each modification would be visible to all implemented backends, possibly preventing correct processing whenever a transformation is not appropriate for a given target. Subsequently, the routine checks whether an equations block is present. Obviously, no modifications are required if no equations are given, thus the operation terminates and returns the current working copy. Otherwise, the content of the neuron’s equations block is delegated to the previously introduced SymPySolver class. Depending on the results as returned by the ODE-toolbox, a different handling is employed: In the case that at least one kernel and exactly one equation are contained in the textual model, the toolbox is most often able to compute an exact solution. Computed modifications of this type contain new variables and assignments, thus the task to transform the processed working copy is delegated to the ExactSolutionTransformer class. Expecting a JSON string, this class parses and injects all returned modifications into the processed AST. In cases where a given equations block contains only kernels, the ODE-toolbox tries to derive a solution where kernels are replaced by equations and initial values, making the computation less time and resources consuming. The corresponding adaption of the AST is delegated to the KernelsToOdesTransformer class which replaces kernels by their computed ODE counter pieces. The ExactSolutionTransformer and KernelsToOdesTransformer classes hereby import the assisting TransformerBase class. This component contains general functionality as required to process both types of returned solutions, e.g., the applyIncomingSpikes method which replaces all convolve function calls in the equations block by concrete update instructions, e.g., assignments of values stored in buffers to state-variables. For certain types of declarations, the ODE-toolbox by Blundell et al. is not able to derive a more efficient solution [4]. In these cases, the NEST simulator performs a time-consuming, numeric integration of the unmodified equations block. Not supported declarations as well as errors during the equations block processing are hereby indicated by the status field of the JSON object as returned by the toolbox. In this case, the local working copy of the AST is not further modified but simply returned to the code-generating subsystem. As previously stated, the overall processing implements a transformation which is specific to the NEST simulator. However, other backends may also reuse parts of the presented classes. Consequently, all concrete transformations as implemented in the ExactSolutionTransformer, KernelsToOdesTransformer as well as the TransformationBase class have been summarized in a dedicated module.
The optimized representation of the source model is returned to the orchestrating analyseAndGenerateNeuron method of the NestCodeGenerator class. Here, it is first prepared for the code generation by retrieving general characteristics and setting up a generation context which states, e.g., whether a spike buffer is contained in the model. Subsequently, a template engine and a set of templates are used to generate model-specific C++ code. The result of this step is an executable representation of a source model as well as a set of additional artifacts which can now be used to integrate the neuron model into the NEST simulator.
Jinja2, as well as many other template engines, often do not directly interact with the AST, but follow a more general concept by operating on a generation context. Such a context consists of a map from identifiers to objects, methods and other properties. For instance, if the generating routine has to be able to interact with the ASTUtils class, it is required to create a dictionary mapping a unique identifier to an ASTUtils class reference. This identifier can then be used in the context of the template to interact with the corresponding object. Before the code generation is invoked, it is therefore first necessary to set up a generation context. In the case of PyNESTML, this context consists of several processed objects as well as assisting classes, cf. fig_higher_order_visitor. For the sake of modularity, the creation of an appropriate context is delegated to the setupStandardNamespace function which instantiates a generation context according to the handed over AST.
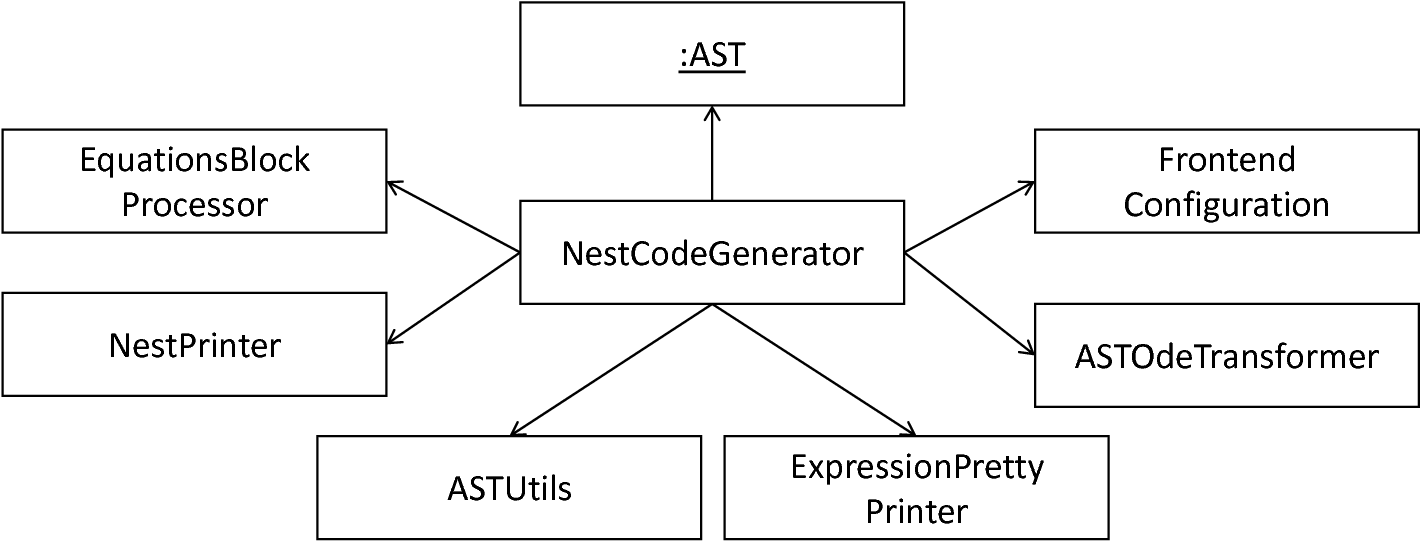
The NESTCodeGenerator class and assisting components.
Having a set up context, the NestCodeGenerator initiates the actual code generation by invoking the render operation on the further on introduced templates, with the result being a set of generated C++ artifacts as illustrated in fig_generated_artifacts_izhikevich. In order to enable an easy to achieve integration of the generated C++ code into the NEST infrastructure, PyNESTML implements a concept for the generation of setup files. By utilizing predefined extension points of NEST, new neuron models can be integrated into the simulation environment by means of a corresponding module file. The task of generating these artifacts is delegated to the generateModuleCode procedure. Except for a different set of templates, this method behaves analogously to the above-introduced generateModelCode procedure. After all model-specific as well as setup artifacts have been generated, the control is returned to the PyNESTML workflow unit.
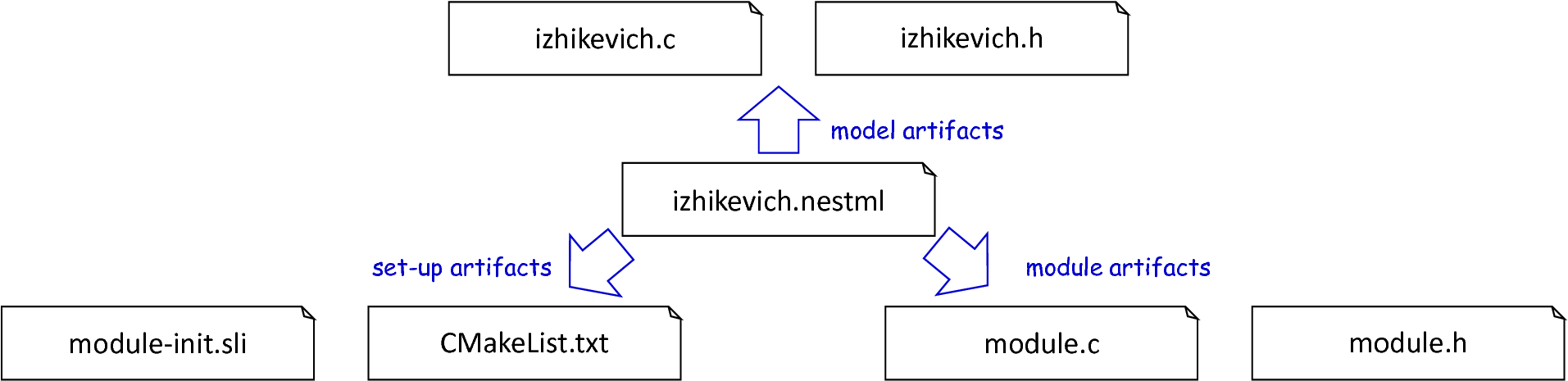
Generated artifacts of the Izhikevich neuron model.
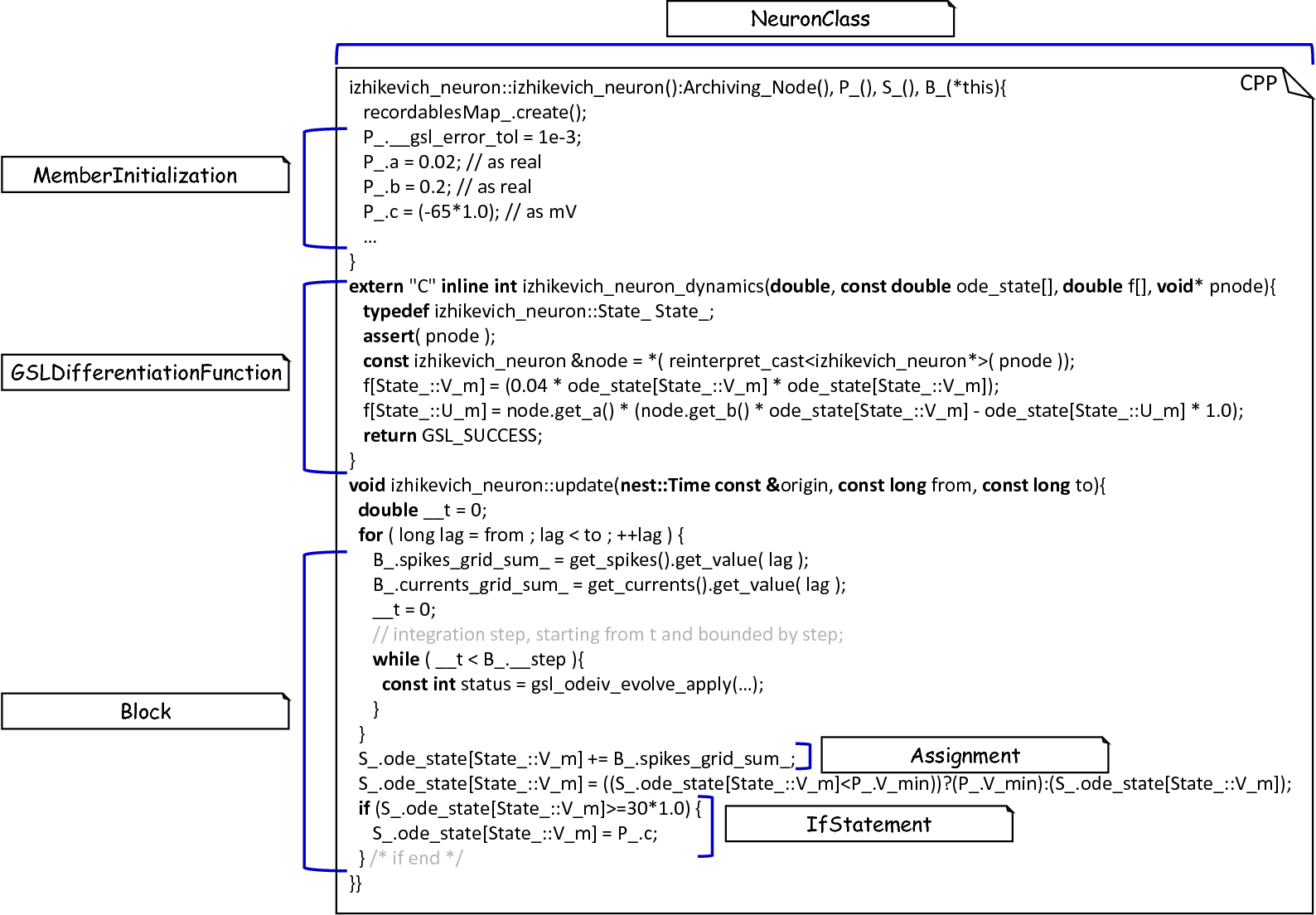
Templates and the generated code of the Izhikevich neuron model.
Target implementations can often be described in a schematic way by means of a template, where placeholders are replaced by model-specific details in order to get executable, concrete code. These templates represent a major component of a code generator and are used by the above-introduced routines, e.g., the generateModelHeader method. The implemented NEST backend employs six governing templates and a set of assisting sub-templates. Models of neurons are generated by means of the NeuronHeader and NeuronClass template, while the generation of a model integration file is delegated to the ModuleHeader and ModuleClass templates. The generation of setup files is delegated to the SLI_Init and CMakeList templates. fig_templates_generated_code_izhikevich exemplifies how templates are used by means of generated C++ code. The processing as executed by the generator engine involves a retrieval of data from the model’s AST and the symbol table, and a replacement of placeholders in the evaluated template. All required declarations are hereby extracted from the AST by the corresponding getter operation, e.g., getStateSymbols, and stored in C++ syntax.
Context sensitive target syntax.
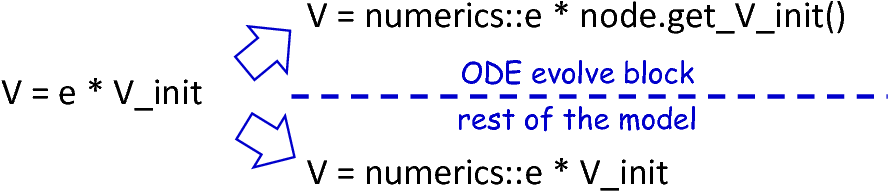
While templates, in general, are able to depict an arbitrary syntax, their usage can become inconvenient whenever many cases have to be regarded and conditional branching occurs. This problem becomes more apparent when dealing with expressions: While the overall form of the AST is restructured to be more NEST affine, individual elements remain untouched and are still represented in PyNESTML syntax. However, certain details such as the used physical units are not supported by NEST. It is therefore required to transform atomic elements such as variables and constants to an appropriate representation in NEST. Moreover, in a single model it may be necessary to represent a certain element in different ways, cf. fig_context_sensitive_target_syntax. Consequently, it is not possible to simply modify the AST to use appropriate references and definitions. PyNESTML solves this problem by using an ad-hoc solution as implemented in the ExpressionPrinter class. Mostly used whenever expressions have to be printed, this class is able to generate a handed over AST object in a specified syntax. Similar to the type deriving routine, cf. Section 1: The model-processing Frontend, the ExpressionPrinter class first descends to the leaves of a handed over expression node. Subsequently, all leaf nodes are printed to a target-specific format, before being combined by counter pieces of the stated operators. This process is executed until the root node has been reached. The returned result is then used to replace a placeholder in the template by a string representation of the expression.
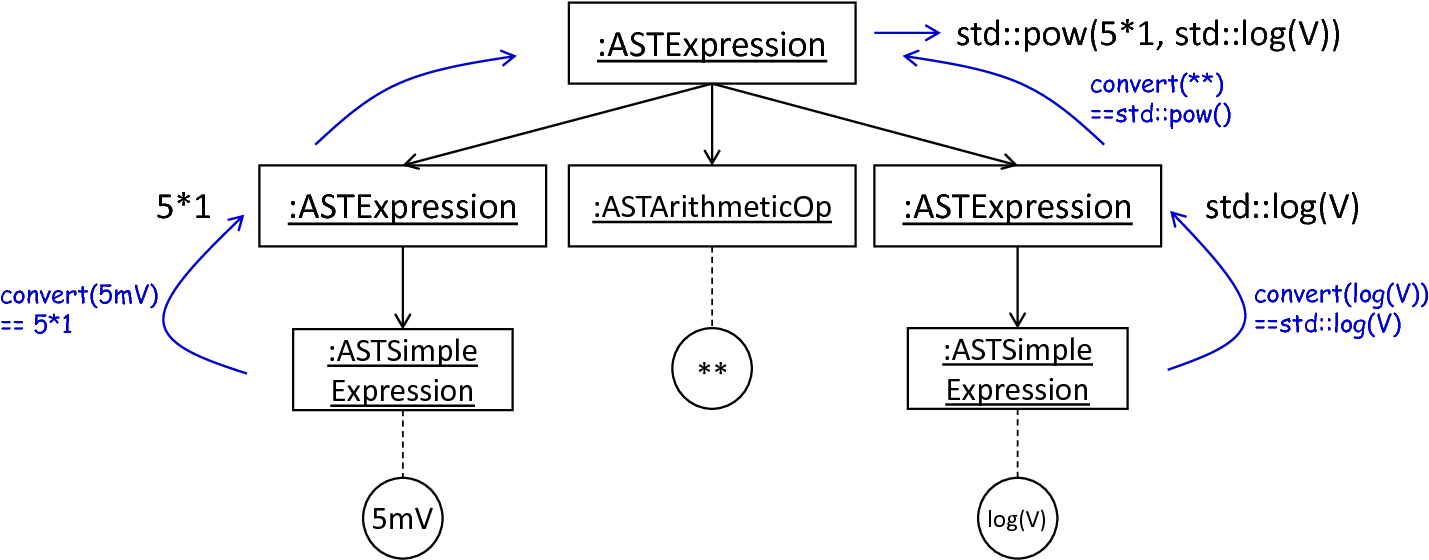
The key principle of the ExpressionPrinter class is its composable nature: While the ExpressionPrinter only dictates how subexpressions and elements have to be printed and combined, the task to derive the actual syntax of elements and operators is delegated to so-called name printers. Implementing the template and hook pattern [6], here it is possible to utilize different name printers to print elements and operators into a different syntax. fig_astexpression_to_string demonstrates how expressions are transformed to a string representation by utilizing the above-introduced routine.
From ASTExpression object to a string.
The abstract VariablePrinter class declares which operations concrete name printer classes have to implement. Besides converting functions for binary as well as unary operators, it is also necessary to map variables, constants and function calls. All these elements are therefore provided with their respective convert functions expecting an AST node of a corresponding type. The ExpressionPrinter class hereby stores a reference to the currently used name printer, which is then used to convert the above-mentioned elements. The separation of a name printer and the expression printer leads to an easily maintainable and extensible system: Similar to the visitor pattern, cf. Section 2: Assisting Classes, where only the visit method has to be adjusted, here the user can simply replace or extend the name printer without the need to modify the overall printing routine. Moreover, the code-generating routine becomes composable, where the implemented expression printer can be independently combined with different name printers.
The NESTVariablePrinter is the first concrete implementation of the VariablePrinter class and is used whenever concepts of NESTML have to be converted to those in NEST. Being used in almost all parts of the provided templates, this class features a conversion of operators and constants to their equivalents of the NEST library. As illustrated in fig_astexpression_to_string, each element of a given expression is inspected individually and a counter piece in NEST is returned, making the generated code semantically correct and references valid. The GSLVariablePrinter class implements the handling of references which is only required in the context of equation blocks. NEST utilizes GSL for the evolvement of equations. Consequently, references as stated in the equations block have to resolve to elements of GSL. The GSLVariablePrinter hereby inspects the handed over element and returns the respective counterpiece. If a mapping is not defined, the element is simply returned without any modifications.

Adaption of syntax by the convertToCPPName method.
C++ as well as many other languages does not support the apostrophe as a valid part of an identifier. Consequently, variables stated together with their differential order cannot be directly generated as C++ code. PyNESTML solves this problem by implementing an on-demand transformation of names, executed whenever a variable is processed during code generation. In the case that the name of a generated element contains an invalid literal, PyNESTML employs the convertToCPPName operation which prefixes a variable for each stated order by the letter D, cf. fig_syntax_by_converttocppname, resulting in a valid C++ syntax. Moreover, as illustrated in fig_templates_generated_code_izhikevich, generated code features information hiding where attributes of objects and classes can only be accessed by the corresponding data access operations. Together with the convertToCPPName function, a conversion of names and references to their respective data access operation is implemented in the NestNamesConverter, respectively GSLNamesConverter class for the processing of equations. Both elements are accessed during code generation and the usage of the ExpressionPrinter class.

Mapping of NESTML types to NEST.
The second type of assisting component, namely the NestPrinter class, is used across the overall backend and implements several methods as often required. The printOrigin method, for instance, states from which type of block the corresponding variable or constant originates. Depending on the origin, a different prefix is attached, e.g., S_. for state or P_. for parameters. Such a handling is required given the fact, that all attributes in the generated code are stored in structs [7] of their respective types. By prefixing an element’s name by a reference to its structure, the correctness of generated code is preserved.
The CppTypeSymbolPrinter class provides a mapping from NESTML types to appropriate types in C++, cf. fig_mapping_nestml_types_to_nest. It should be noted that NESTML buffers represent variables and consequently have to be declared with a respective type. For this purpose, NEST’s implementation of the RingBuffer is used as the corresponding counter piece. Whenever an element is generated, the functionality contained in the CppTypeSymbolPrinter class is used and an appropriate NEST type is returned.
Common neuroscientific physical units.
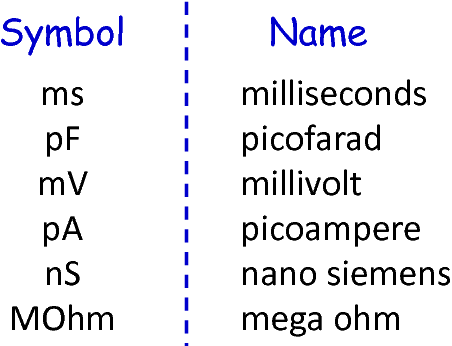
In the case of physical units, additional handling is required. NEST assumes that only a restricted set of physical units, the so-called common neuroscientific units as illustrated in fig_common_neuroscientific_units, are used. In the case that a given constant or variable utilizes a physical unit, the corresponding C++ code is generated without any units and only the numeric part is regarded. Nonetheless, to preserve semantical equivalence of the generated code and the source model, the scalar of a unit is derived in the following manner: In the case that an atomic unit is given, e.g., mV, PyNESTML checks whether it is a common neuroscientific unit or not. If so, the neutral scalar 1 is returned. Otherwise, the value is scaled in relation to its common neuroscientific unit, e.g., V is converted to mV and the scalar 1000 is returned. In the case that a compound unit is used, e.g., mV*s, the evaluation is executed recursively and all scalars combined. fig_conversion_physical_units_nest illustrates this procedure. The UnitConverter class implements a routine which is able to perform these steps and scale values according to their physical units. This component is invoked during the generation of expressions and declarations to C++ code and preserves semantical equivalence of the initial model and the generated code.
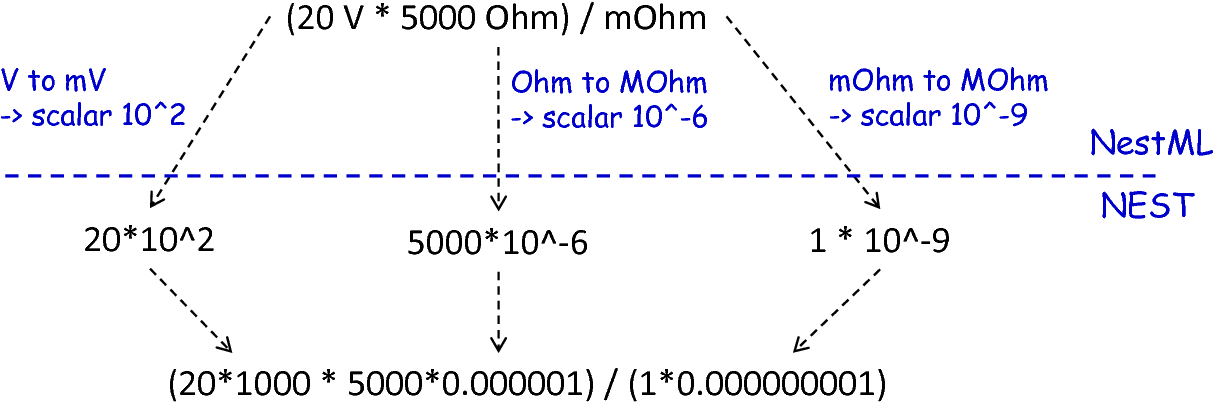
The conversion of physical units from PyNESTML to NEST.
However, a mapping of physical units to their respective scalars is not bijective. For instance, the scalar 1000 in a transformed expression could originate from the unit volt or second, or be a simple scalar stated in the source model. Such a handling makes troubleshooting of generated code complex where the origin of an element is not directly clear. This problem is solved by the NESTMLPrinter class, a printer which implements a simple identity mapping, i.e., all elements are converted back into NESTML syntax. This class is used during the generation of a model’s documentation where all variables, types, as well as references, are generated in plain NESTML syntax.
Together with the above-presented set of assisting classes, the functionality as implemented in the ExpressionPrinter class enables PyNESTML to print complex expressions and other declarations without utilizing templates with cascaded branching and sub-templates for the generation of atomic parts, e.g., function calls. The result is an easy to maintain set of components, where complexity is distributed across several subsystems and no god classes or templates [8] are used.
Section 3.2: Summary of the code-generating Backend
We conclude this chapter by a brief overview of the implemented routines. Section 3.1: AST Transformations and Code Generation demonstrated how NEST-specific C++ code can be generated from an optimized AST. Here, we first introduced the coordinating NestCodeGenerator class and showed how code generation is prepared. To this end, we outlined how declarations of models can be optimized by restructuring the equations block to a more efficient form. The computation of the optimizations is hereby delegated to the ODE-toolbox by Blundell et al. In order to integrate the results as returned by the toolbox, we implemented the EquationsBlockProcessor and its assisting classes. Together, these two components yield a more efficient definition of a model. Subsequently, we highlighted a set of templates used to depict the general structure of generated C++ code. In order to reduce the complexity in the used templates, PyNESTML delegated the task of generating expressions to the ExpressionPrinter class. Together, these components implement a process which achieves a model to text transformation on textual models.
PyNESTML has been developed with the intent to provide a base for future development and extensions. As we demonstrated in Section 3.1: AST Transformations and Code Generation, the transformation used to construct NEST-affine and efficient code has been called from within the NEST code generator as a preprocessing step. Future backends for target platform-specific code generation can, therefore, implement their individual and self-contained transformations, while all backends receive the same, unmodified input from the frontend. Individual modifications of the AST can be easily implemented as composable filters in the AST processing pipeline. Nonetheless, some of the model optimization steps are of target platform-agnostic nature, e.g., simplification of physical units, and are therefore implemented as a target-unspecific component in the workflow. Moreover, the key principle of the ExpressionPrinter, namely its composability by means of name printers, represents a reusable component which can be used for code generation to arbitrary target platforms. All this leads to a situation where extensions can be implemented by simply composing existing components.