Section 1: The model-processing Frontend
In this section we will demonstrate how the model-processing frontend of PyNESTML is structured. To this end, it is first necessary to parse a textual model to an internal representation by means of a lexer and parser. Section 1.1 introduces this subsystem together with a collection of AST classes and the ASTBuilderVisitor, a component which extracts an AST representation from a given parse tree. Subsequently, the CommentCollectorVisitor and its underlying process responsible for the extraction of comments from the source model and their correct storing in the AST is demonstrated, making the generation of self-documenting models possible. Having a model’s AST, it remains to check its semantical correctness. For this purpose, Section 1.2 will first introduce a data structure for the storage of context-related details, namely the Symbol classes. Here, we also show how modeled data types can be represented and handled. In order to provide a basic set of constants and functions predefined in NESTML, the predefined subsystem is implemented. With a parsed model represented by the respective AST, and a structure for storing context information, the frontend proceeds to collect context related details of the model. Demonstrated in Section 1.3 together with the SymbolTable and a set of context conditions, the ASTSymbolTableVisitor ensures semantical correctness. After all context conditions have been checked, the frontend’s model processing is complete. All steps outlined above are orchestrated by the ModelParser class which represents the interface to the model-processing frontend. fig-frontend-overview subsumes the concepts demonstrated in this chapter. In order to avoid ambiguity, we refer to the framework as PyNESTML, while the processed language itself is called NESTML.
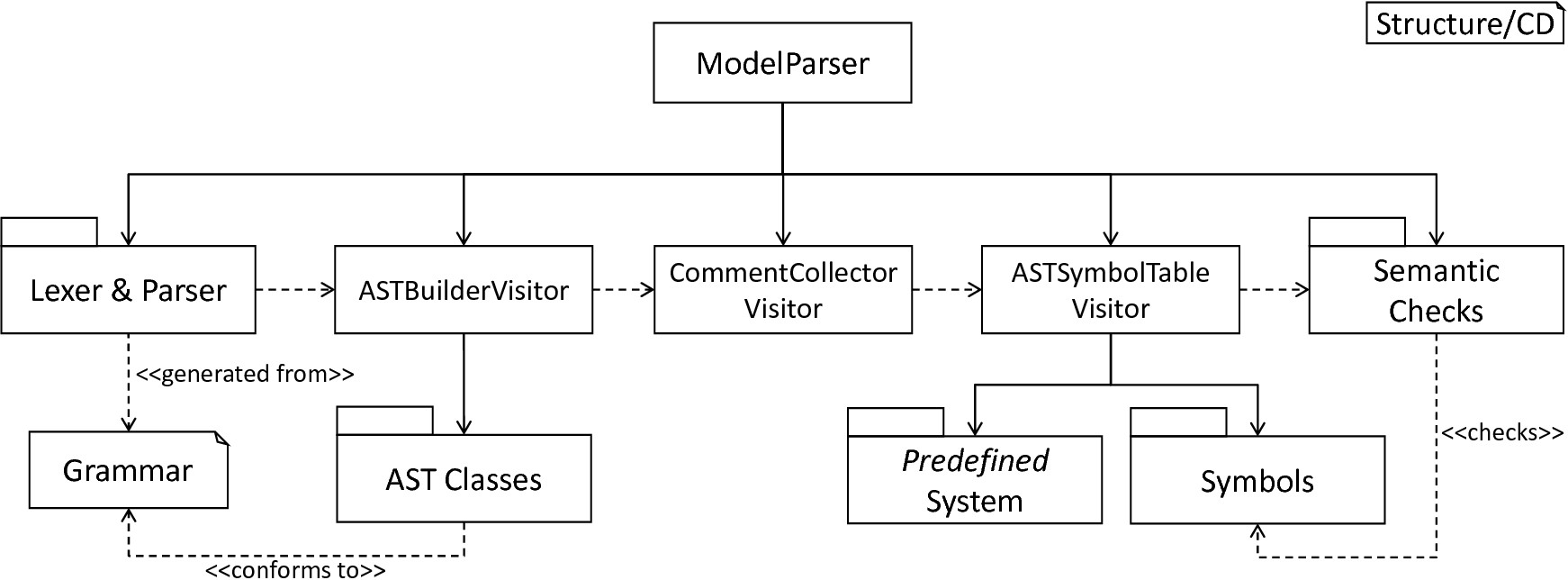
Overview of the model-processing Frontend: The lexer and parser process a textual model to the corresponding parse tree and can be completely generated from a grammar artifact. The ASTBuilderVisitor is responsible for the initialization of a model’s AST, employing classes which conform to the DSL’s grammar. After the AST has been constructed, the CommentCollectorVisitor collects and stores all comments stated in the source model. The ASTSymbolTableVisitor subsequently collects context information of the model by utilizing Symbols and the predefined subsystem. Semantic Checks conclude the processing by checking the model for semantical correctness. All steps are orchestrated by the ModelParser.
Section 1.1: Lexer, Parser and AST classes
The first step during the processing of a textual model is the creation of an internal representation by means of an AST. For this purpose, it is first necessary to implement a lexer and parser which read in a textual model and create a respective parse tree. However, the parse tree represents an immutable data structure where no data retrieval and modification operations are provided, making required transformations and interactions difficult. Consequently, a refined representation in the from of an AST has to be derived. It is therefore necessary to implement a collection of AST classes used to store individual elements of the AST. In order to retrieve all required information from the parse tree and instantiate a respective AST, the ASTBuilderVisitor is implemented. The result is a model’s AST which can be used for further checks and modifications. All these steps are encapsulated in the orchestrating ModelParser class. fig-lexer-parser-overview provides an overview of the components as introduced in this section.
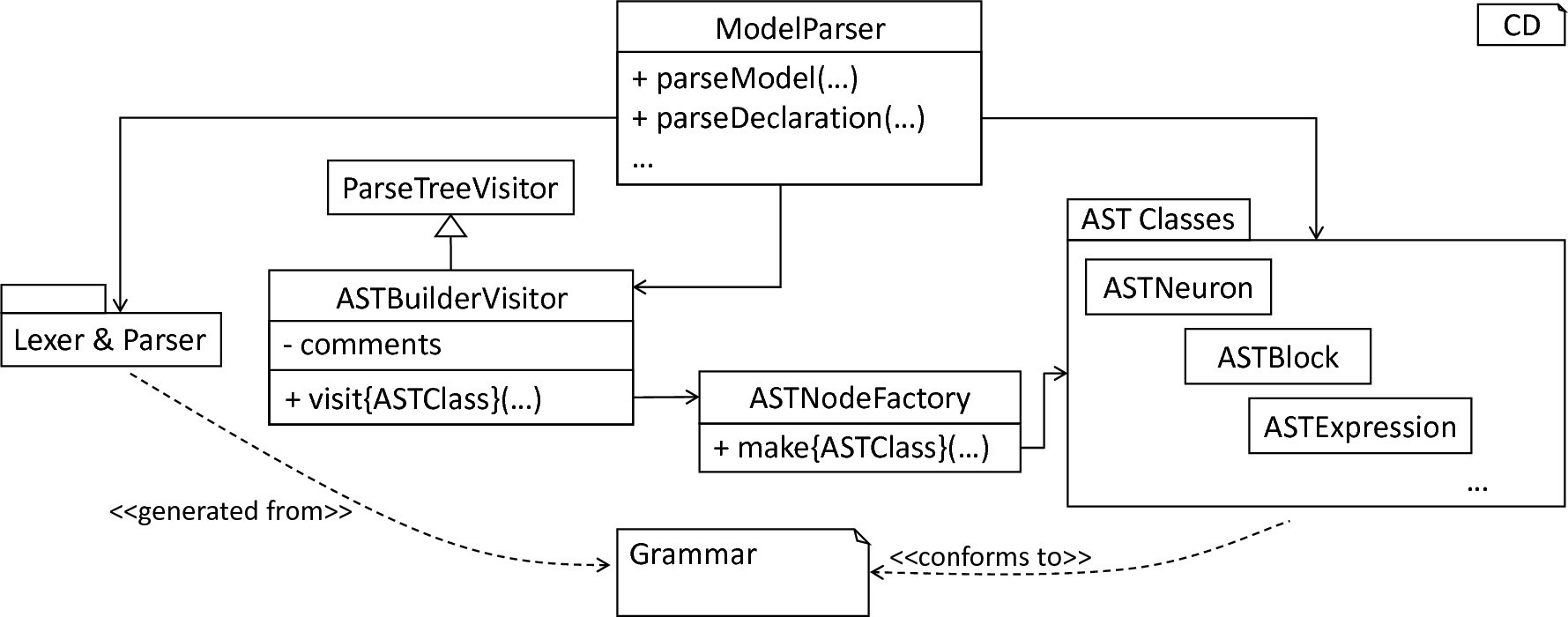
Overview of the lexer, parser and the AST classes: The grammar represents the artifact from which the lexer and parser are generated. Moreover, the ASTBuilderVisitor class extends the generated ParseTreeVisitor class and transforms the handed over parse tree to the respective AST. The ASTNodeFactory features a set of operations for node initialization. The ModelParser encapsulates all processes and can be used to parse complete models or single statements.
Although possible, lexer and parser are usually not implemented by hand but rather generated from their respective grammar. In the case of PyNESTML, Antlr was selected to define the grammar and generate the lexer and parser. For this purpose, it is first necessary to create the grammar of the language. Although modular and easy to understand, PyNESTML’s grammar is still an artifact of several hundreds lines of code. In the following we will therefore use a simplified working example as depicted in fig-simplied-grammar. The grammar as used to define the complete language can be found here. The grammar is hereby an artifact structured according to Antlr’s syntax and defines which rules and tokens the language accepts. All concepts as introduced for the working example are implemented analogously for the complete grammar.

A simplified grammar: Each neuron model is introduced by the keyword neuron and the neuron’s name. A model is composed of an arbitrary number of blocks consisting of a name and a set of declarations and assignments. Declarations consist of a name, the data type and a value-defining expression, while assignments only utilize a left-hand side name and a value-providing expression. Expressions are either simple, i.e., a string, boolean or integer literal, or arithmetic combinations of other expressions.
Starting from the grammar, Antlr is used to generate the respective lexer and parser, making an error-prone implementation by hand unnecessary. A shell script is provided that encapsulates the invocation to Antlr4 and command-line parameters, and can be found in pynestml/grammars/generate_lexer_parser. It will generate the lexer, parser and visitor components in the directory pynestml/generated. The files in this directory are not intended to be edited by hand, but must always be generated on the basis of the grammar.
Consequently, these components can be used in a black-box manner, where only the interface is of interest. The generated lexer expects a file or string to parse, and returns the respective token stream. Storing and interacting with the stream of tokens can be beneficial whenever a derivation of additional details in the initial model is required, e.g., the model comments. The token stream is handed over to the parser which creates a parse tree representation of the model according to the grammar rules. Both steps as well as the derivation of an AST are encapsulated in the ModelParser class whose parse_model behavior is illustrated in fig-model-parsing-process.
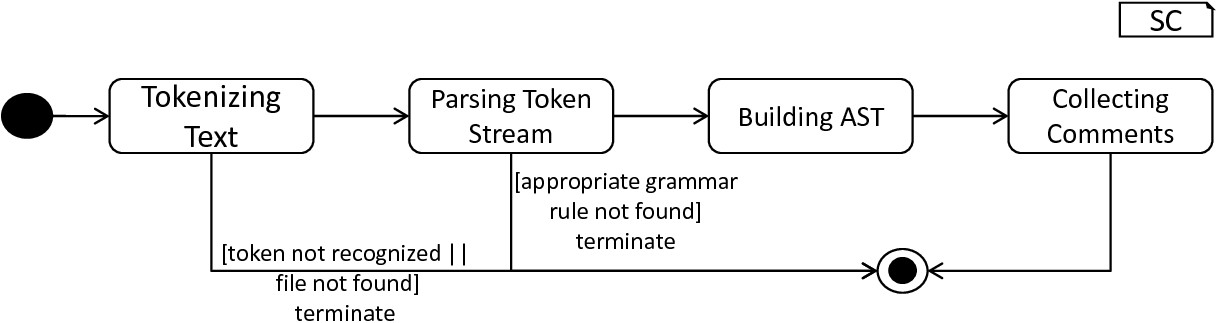
The model-parsing process: First, a model is decomposed into a stream of token objects. If a literal in the model is not constructed according to the token definitions, the process is terminated and the problem reported. Otherwise, the token stream is handed over to the parser which constructs a parse tree by taking the grammar rules into account. For sequences of tokens which are not constructed according to a grammar rule, an error is reported and the process terminated. A constructed parse tree is handed over to the ASTBuilderVisitor which constructs the respective AST. Finally, all comments are retrieved and stored.
Besides complete models, it is also often of interest to parse single instructions or expressions from a given string, e.g., for AST-to-AST transformations. The ModelParser class therefore provides parsing methods for each production in the grammar artifact, which can then be used to parse the respective element directly from a given string. In all cases, first, the parse tree is created by means of the generated lexer and parser. Subsequently, the further on introduced ASTBuilderVisitor is used to derive a respective AST representation.
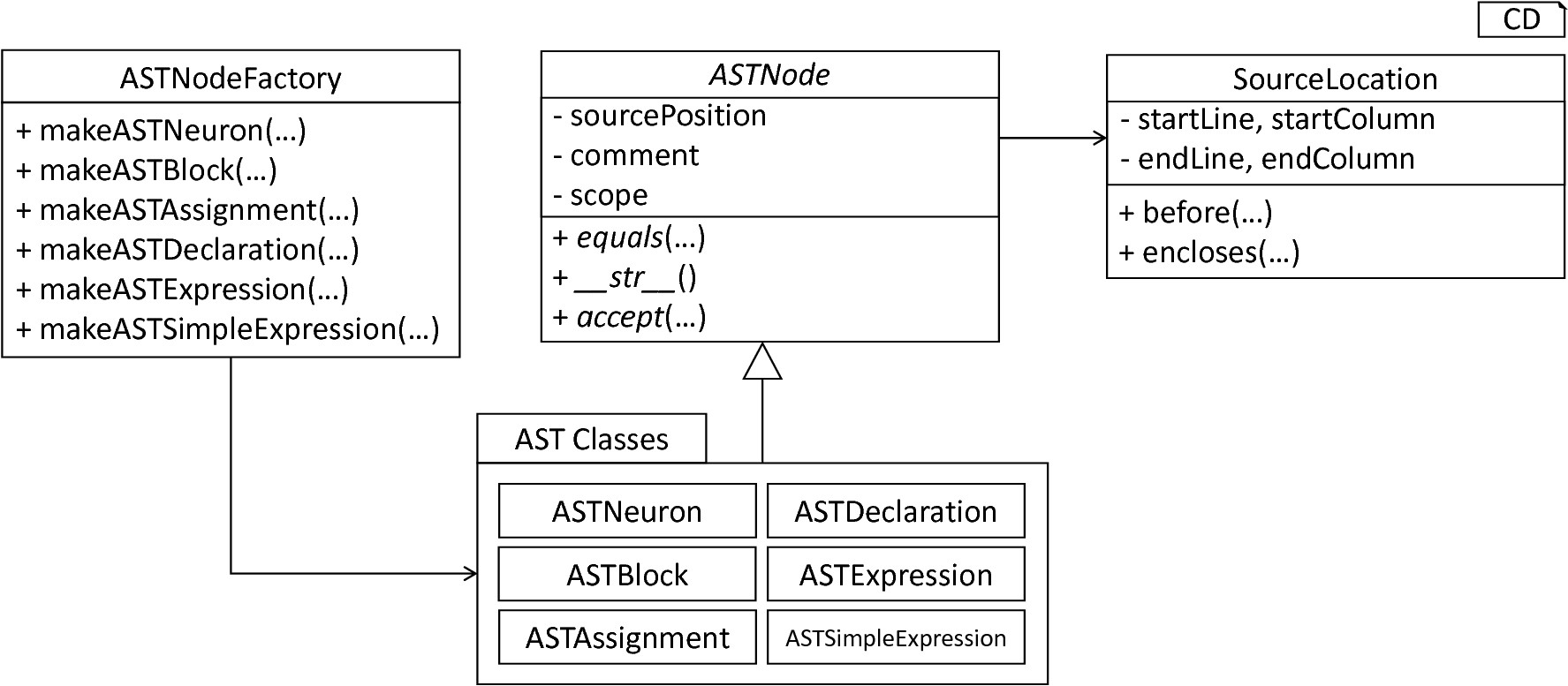
Overview of the AST classes: The ASTNode represents a base class for all concrete AST classes. Each AST node stores a reference to a SourceLocation object, representing the position in the textual model where the element has been defined. The ASTNodeFactory is used to create new instances of AST nodes.
AST classes couple fields for all required values with data retrieval and modification operations. The abstract ASTNode class represents the base class which is extended by all concrete node classes. It implements features which are common for all concrete nodes, namely the source location of the element, a comment field as well as a reference to the respective scope of the element, cf. Section 1.3 . Moreover, it prescribes abstract methods which have to be implemented by all subclasses: The equals method can be used to check whether two objects are equal in terms of their properties, while an overwritten __str__ method returns the element in a human-readable form. The concrete accept method is used by the further on introduced visitors in order to interact with the object.
A source location is an object of the SourceLocation class. By encapsulating this property in a separate class it is possible to provide a set of common utility. Among others the following two methods were implemented: The before function checks whether the current source location in the model is before a handed over one, while the encloses function indicates whether one source location encloses a different one.
Concrete AST classes are implemented according to the DSL’s grammar. Explicit terminals such as the plus symbol are indicated by boolean fields, e.g., storing true whenever a respective terminal has been used. Implicitly declared terminals, e.g., NAME, are stored with the values stated in the textual model. References to sub-productions such as the simple expression are treated in the same manner, although here a reference to the initialized AST node of the sub-production is stored. Besides standard functionality for the retrieval of data, each AST class inherits and implements all operations as declared in the abstract ASTNode class. fig-grammar-to-ast-classes illustrates how the ASTExpression and ASTSimpleExpression classes are constructed from the respective production in the grammar.
Due to Python’s missing concept of method overloading, it is not possible to define several standard constructors for a single AST class. This problem is tackled by means of the factory pattern [5]. For each instantiable node, the ASTNodeFactory class defines one or more operations which can be invoked to return a new object of the respective class, cf. fig-overview-ast-classes. By providing all functions with a distinct name, method overloading is avoided.
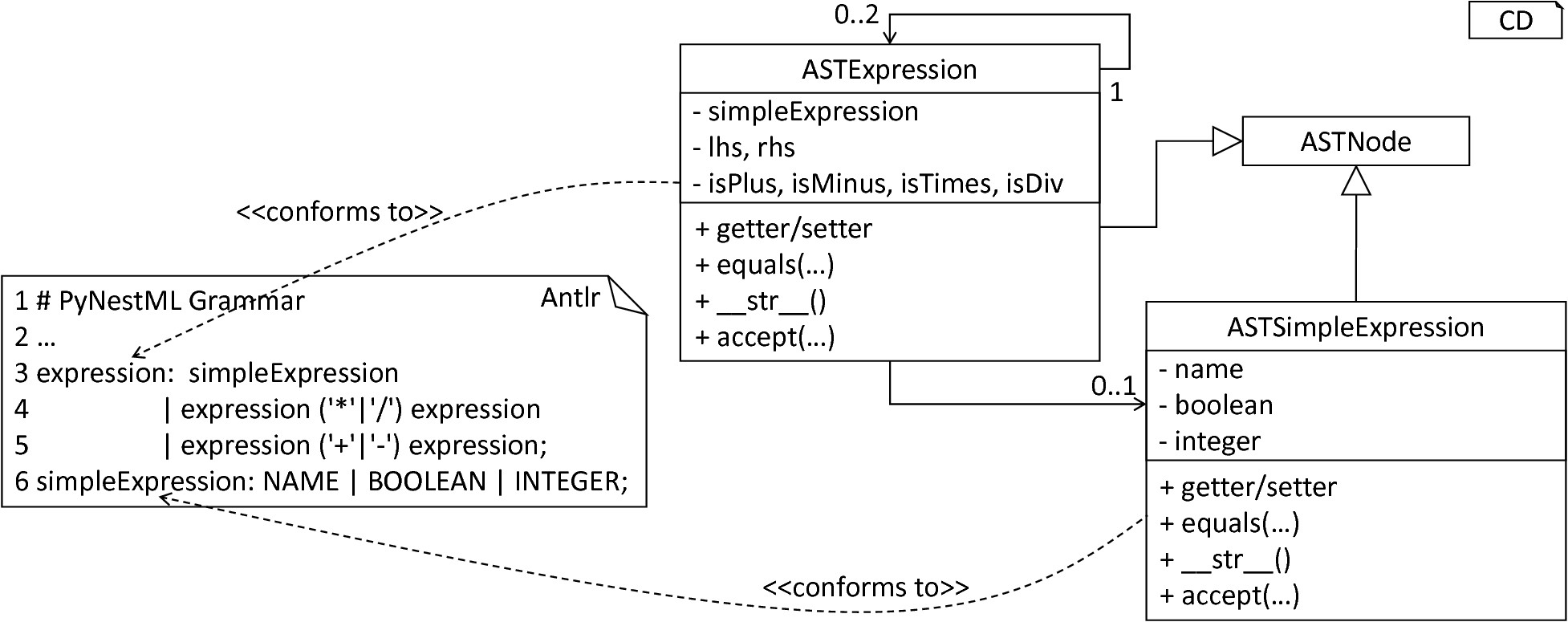
From Grammar to AST Classes: Each production in the grammar is used to construct a new AST class. For each terminal and referenced sub-rule, an attribute is created. A set of operations provides functionality for the visualization of nodes, data retrieval, and manipulation.
The ASTBuilderVisitor class implements a parse tree visiting process which initializes the respective AST representation. As demonstrated in fig-ast-simpleexpression-node-creating, the processing encapsulated in this class visits all nodes in a model’s parse tree and creates AST nodes with the retrieved information. The parse tree stores all terminals, e.g., numeric values, as strings. For token classes which model value classes, e.g., strings or numeric values, their values are stored in correctly typed attributes of the AST. For each field of a parse tree node, the ASTBuilderVisitor therefore checks whether a value is available, e.g., a stated numeric literal. In cases where a value has been provided, it is retrieved, correctly casted and stored in the AST node. For non-terminals, the procedure is executed recursively by calling the visit method. The result is an initialized AST.

The ASTSimpleExpression node creating method: With the overall structure of the DSL in mind, this method is constructed to directly store correctly typed values. The position of the element in the model is retrieved and stored in a new SourceLocation object. Finally, a new AST node is created by the respective factory method.
Although not crucial for the correct generation of a model implementation, comments as contained in the source model can be beneficial whenever an inspection of generated code is necessary. Here, it is often intended to retain source comments. As declared in fig-simplied-grammar, the lexer hands all elements embedded in comment tags over to a different token channel. Each comment is delegated to the comment channel, where all comment tokens are stored and retrieved whenever required. In order to extract and transfer comments from tokens to their respective AST nodes, the CommentCollectorVisitor has been implemented, cf. fig-comment-collector-visitor.
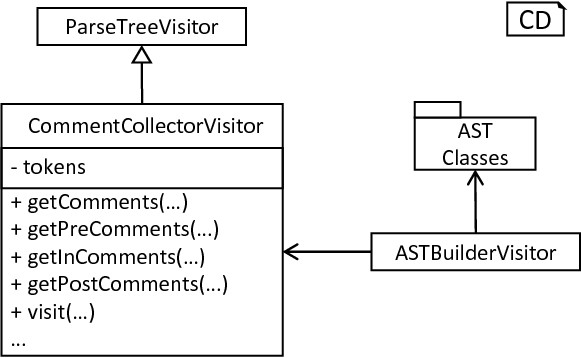
The CommentCollectorVisitor: The visitor implements a process for the collection of comments in arbitrary nodes of the parse tree. In order to simplify the processing, merely the visit method has to be called. This method delegates the work to the get_comments function and finally returns all collected comments. The comment collector extends the ParseTreeVisitor and is called within the ASTBuilderVisitor whenever an AST is constructed.
It inspects the token stream and retrieves all comments which belong to the corresponding node. For this purpose, the CommentCollectorVisitor stores a reference to the initial token stream. Moreover, four methods are provided: The get_comment function represents the orchestrating method and is used to invoke the collection of all pre-comments (stated before a statement or block), the in-comments (single line comments in the same line) and finally the post-comments stated after a statement or block in the textual model. In the following, we exemplify the processing of pre-comments, the same procedure is applied analogously for the collecting of in- and post-comments. It should be noted that detection of a comment’s target is ambiguous. For instance, in a situation where two statements with a single comment in between are given without any white-line separating one or the other, it is not possible to determine whether it represents a post-comment of the first statement or the pre-comment of the second one. The following simple yet sufficient concept has been developed: In order to highlight a comment as belonging to a certain element, it is necessary to separate the comment by means of a white-line as demonstrated in fig-comment-processing-routine. In the case that no white-line is injected, the comment is handed over to the previous and subsequent element. The user is therefore able to denote which comments belong to which element by inserting additional newlines.

Illustration of the comment-processing routine: The target of a comment is recognized unambiguously if a separating white-line is inserted, otherwise the comment is added to both enclosing nodes.
The processing of pre-comments is implemented in the following manner: First, the CommentCollectorVisitor checks whether the processed node represents the first element in the artifact (e.g., the first definition of a neuron). In this case, the number of white-lines before the element is not relevant and all preceding comments are stored together with the node. Otherwise, starting from the position of the current context, the token stream is inspected in a reversed order. In the case that a normal element token (e.g., the declaration of a variable) is detected, the loop is terminated since the next element has been reached. If a comment token is detected, then it is put on a stack. Such a handling is required in order to detect whether the comment belongs to the currently handled node, or represents an in-comment of the previous node. If an empty line is detected, then all tokens on the stack are stored in the list of returned comments. Whenever two subsequent white-line tokens have been detected (thus a separating white-line), the overall process is terminated. The visitor returns the collected list of comments in a reversed order to preserve the initial ordering. This process is executed analogously for post-comments. However, here it is not necessary to reverse the list or the token stream. A inverse traversal of the token stream is only necessary to detect where a pre-comment has been terminated. In the case of in-comments, no special handling is implemented. Instead it is simply checked whether before the next end-of-line marker a comment token is contained. To make comments more readable, the replace_delimeters function removes all comment delimiters from the comment string.
Separating the model-parsing and comment-collecting subprocesses leads to an even clearer separation of concerns and benefits maintainability. New types of comment tags can be easily implemented without the need to modify the AST builder. All modifications are therefore focused in the CommentCollectorVisitor, while the initial grammar is kept programming language-agnostic. The comment-collecting operation is invoked during the initialization of an individual AST node in the AST builder.
This section introduced the model-parsing process which constructs the AST from a textual model. Here, we first introduced the starting point of each DSL, namely the grammar artifact, and subsequently outlined how the implementation of a lexer and parser by hand can be avoided by means of Antlr. Instead, these components were generated and embedded into PyNESTML. Due to the missing typing and assisting methods in the parse tree as returned by the parser, a set of AST classes was implemented and introduced in detail. Each class represents a data structure which is used to store details as retrieved from the parse tree. To this end, the ASTBuilderVisitor class and its AST initializing approach were demonstrated. The result of steps introduced above is a parsed model represented through an AST. Finally, the CommentCollectorVisitor demonstated how comments in source models can be collected and stored. Although not crucial for creation of correct target artifacts, comments can still be beneficial for troubleshooting the generated code.
Section 1.2: Symbol and Typing System
Continuing with an initialized AST, PyNESTML proceeds to start collecting information regarding the context. For this purpose, we first establish a data structure for the storage of context related details by means of symbol. Subsequently we demonstrate how predefined properties of PyNESTML are integrated by means of the predefined subsystem. Finally, we show how types of expressions and declarations can be derived.
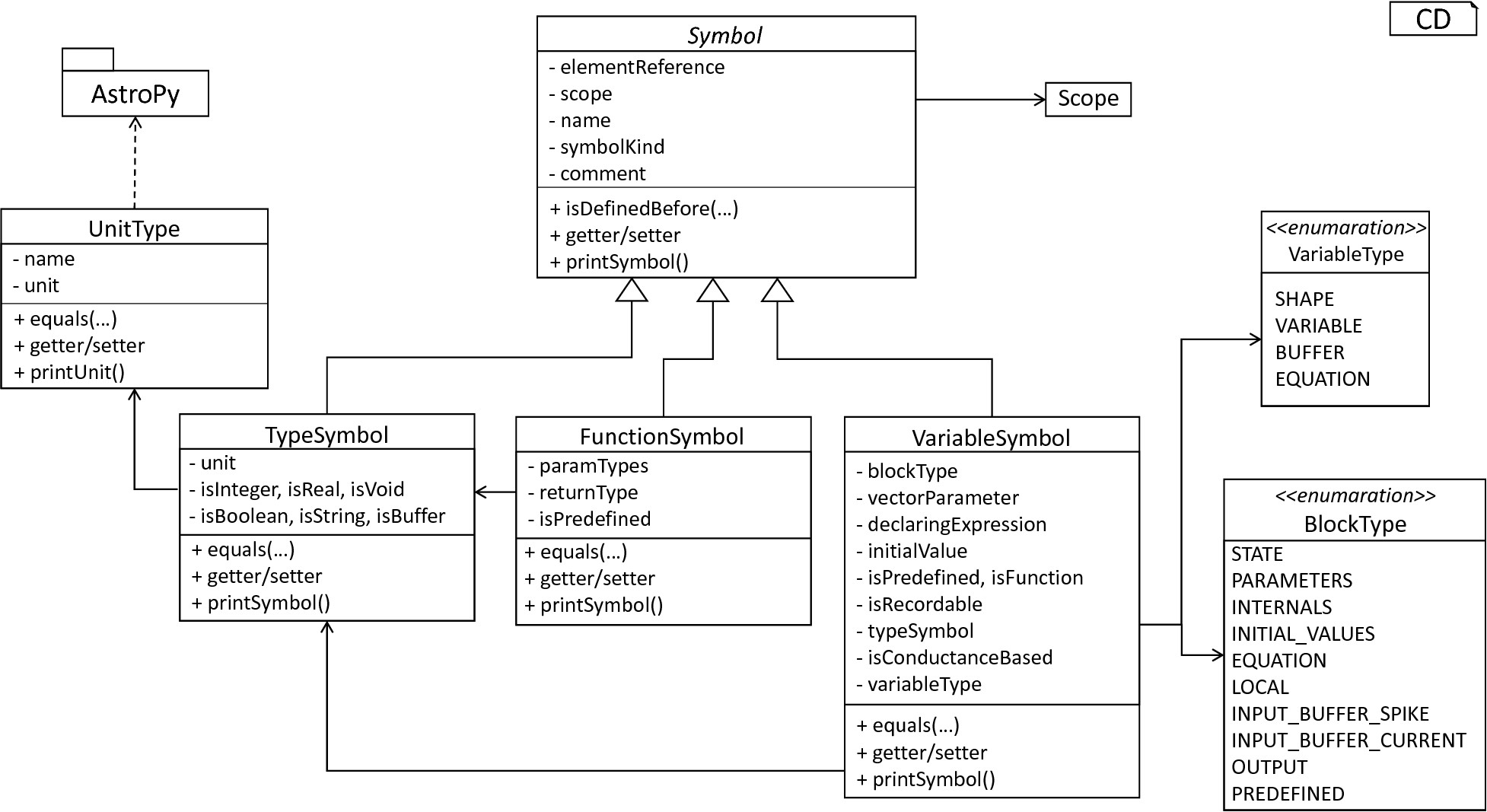
The Symbol subsystem: The abstract Symbol class prescribes common properties. This class is implemented by the TypeSymbol to represent concrete types. FunctionSymbol and VariableSymbol store declared functions and variables. For more modularity, the UnitType class is used as a wrapper around the AstroPy unit system [6]. VariableType and BlockType represent enumerations of possible types of variables and blocks.
The concept of symbols is often used to store details of pre- and user-defined functions and variables. Each defined element is represented by an invididual symbol instance, which can then be used to check the respective context. The abstract Symbol class represents a base class for arbitrary symbols. It features attributes which are common for all concrete symbol types, amongst others a reference to the AST node used to create the symbol, the scope in which the element is located, the name of the symbol and a comment. Besides common data encapsulation methods, only the isDefinedBefore method is provided. This method checks whether a symbol has been defined before a certain source location and is used during semantical checks, cf. Section 1.3. fig-symbol-subsystem provides an overview of classes as implemented in PyNESTML to enable a storage of semantics and types.
A TypeSymbol represents a type as used in declarations and function signatures, and can be either a primitive or a physical unit. In its current state, the type system supports the primitive types integer, real, void, boolean and string. Whether a type is a primitive is represented by a boolean field for each type, while physical units are stored as references to the corresponding UnitType objects. The UnitType class is a simple wrapper for the AstroPy unit system and is used to couple an AstroPy unit object with a processable name as well as equality- and data-access operations. The final attribute of the TypeSymbol class is a boolean indicator whether a buffer or non-buffer type is represented. As indicated in the grammar, spike buffers can be declared with an arbitrary data type. As we will demonstrate in Section 3, the backend utilizes different approaches for the generation of buffer and non-buffer types.
The VariableSymbol class represents the second type of symbols. Each VariableSymbol object symbolizes a variable or constant as defined in the source model. It stores the type of block in which it has been declared as an element of the BlockType enumeration type. According to the grammar, each variable symbol can be defined in a state block, the parameters or internals block, the initial values or equations block. Moreover, given the fact that ports are regarded as variables with stored values, the block types input buffer current, input buffer spike and output are provided. Finally, the type system is able to mark variables as being declared in a local block, e.g., a user-defined function block or the update block, or as a predefined element of PyNESTML, e.g., the global time variable t. The type of a block in which the element has been declared is required for the correct generation of target platform-specific code as introduced in Section 3. PyNESTML marks variables defined in the equations block as being kernels or equations. Variables defined in the input block are marked as being a buffer, while all other elements are simple variables. To this end, the VariableType enumeration type is implemented. By utilizing such a specification it is easily possible to sort symbols according to the property they represent. A corresponding getter function can then be used to retrieve buffers or kernels as required in semantical checks and code generation. The remaining attributes represent a collection of characteristics which are common for declared elements: A variable symbol can have a vector parameter indicating that a vector variable is given. The boolean fields is-predefined, is-function and is-recordable indicate whether the elements have been marked by keywords in the source model or represent predefined concepts, i.e., an element which is always available in PyNESTML as in the case of the global time variable t. The is-conductance-based marks buffers with the unit type Siemens [1], while the type symbol stores a reference to an object representing the type of the variable. The declaring expression as well as the initial value attributes are used in the context of equations. The declaring expression field stores a reference to the expression denoting how new values of the equation have to be computed. Analogously the initial value stores the starting value of a differential equation. In the case that a non-equation symbol is stored, the declaring expression is used to simply store a right-hand side expression.
The FunctionSymbol is the last type of symbol and stores references to pre- and user-defined functions. Consequently, each symbol consists of a name of the function, the return type represented by a type symbol and a list of parameter type symbols. A boolean field indicates whether the corresponding function is predefined or not. In contrast to the variable symbol, function symbols do not feature further specifications or characteristics, e.g., the type of block in which they have been defined. Consequently, only a basic set of data access operations is provided.
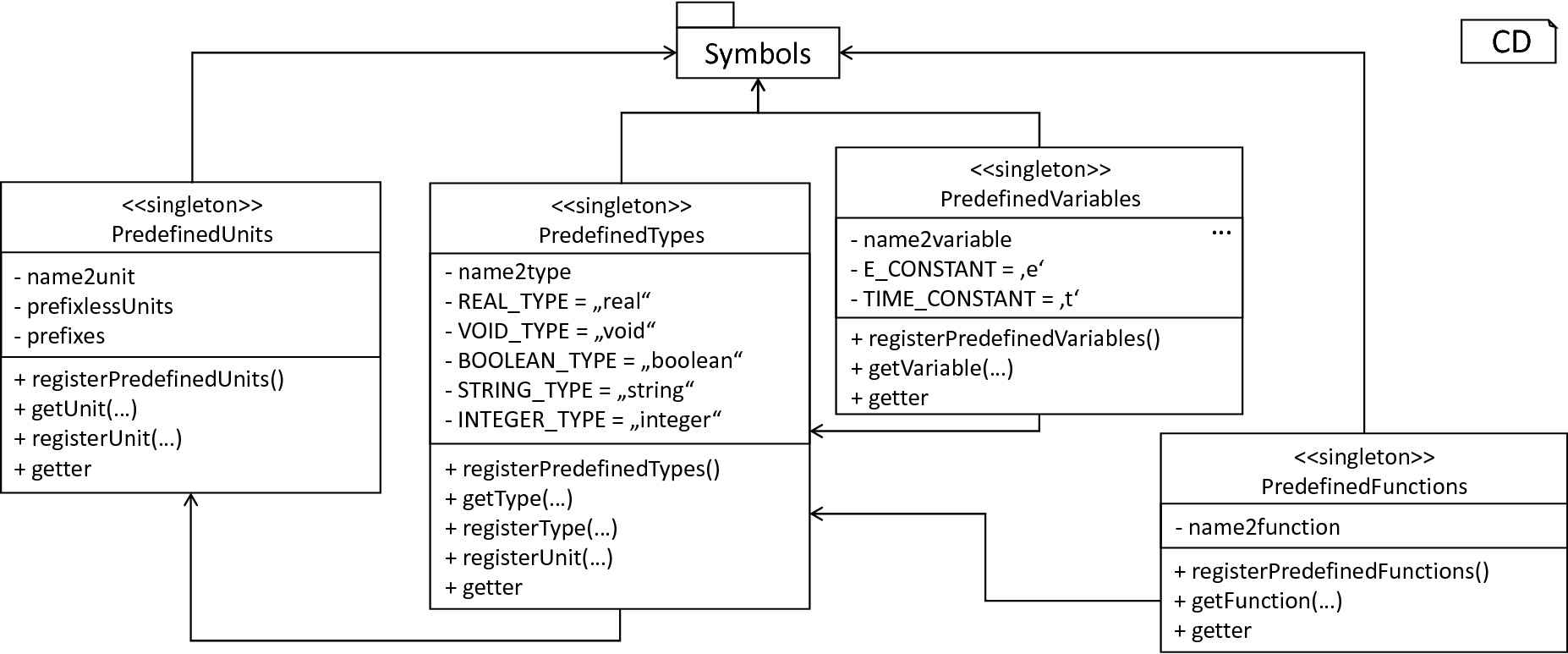
The predefined subsystem: By utilizing the Symbol classes, a collection of UnitType objects is created representing physical units. Together with primitive data types, these units are encapsulated in type symbols and stored in the PredefinedTypes collection, before being used in PredefinedVariables and PredefinedFunctions.
In order to initialize a basic collection of types, variables and symbols, the predefined modules as illustrated in fig-predefined-subsystem are used. All four types of the further on introduced symbol collections ensure that a basic set of components is always available in processed models. In the case of physical units, the units as provided by PyNESTML represent a functionally complete set, i.e., it is possible to derive arbitrary units by combining the provided ones.
The PredefinedUnits class subsumes a routine used to initialize all basic physical units. fig-si-units exemplifies how for each base unit, e.g., volt or newton, and each available prefix, e.g., milli or deci, a combined AstroPy unit is created and wrapped in an object of the previously presented UnitType class. As opposed to variables which are only valid in their corresponding models, units and types are not specific to a certain neuron context, but valid for all possible models. Consequently, PyNESTML stores all types globally for all processed models. The PredefinedUnits class features operations to check whether a given string represents a valid unit definition, e.g., ms, while the getUnit method is used to retrieve the object representing a unit defined by the string. At runtime, often new combinations of existing bases are derived. For instance, in the case of a multiplication of two variables of type ms, it is necessary to derive and register a new unit ms:sup:`2`. While the derivation of new units is delegated to the further on introduced visitors, the registerUnit method can be used to insert a new unit into the type system. An encapsulation of units in the UnitType instances and the storage in the PredefinedUnits collection makes maintenance and extensions easy to achieve: In the case that the given type system is no longer applicable or a new alternative has been found, the corresponding UnitType wrapper can be simply wrapped around a different library without affecting the remaining framework.
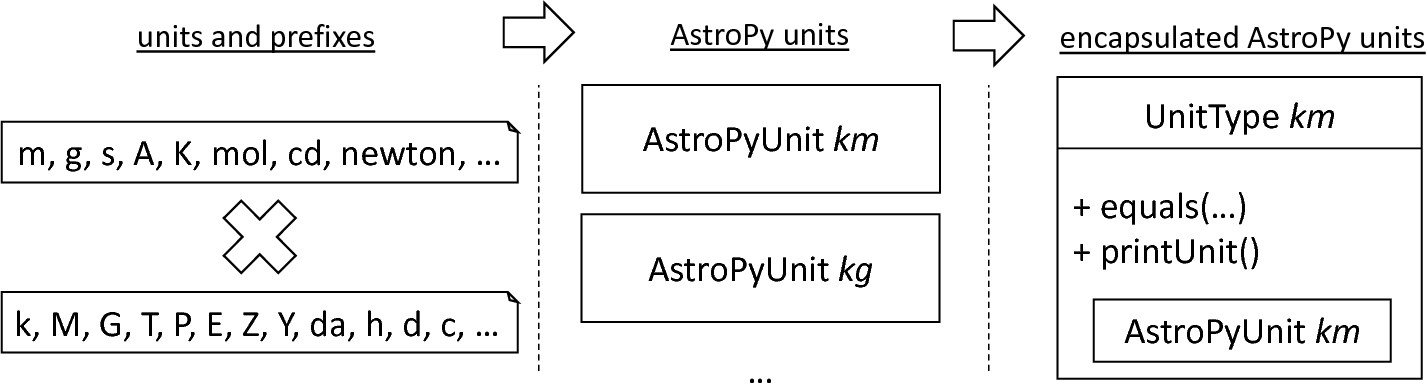
Instantiation of SI units with AstroPy: First, all basic units and all available prefixes are collected in two separate lists. Then, for each unit and each prefix, a combined unit is created, e.g., with the prefix kilo and the unit gram, a new unit kg is initialized. Each created unit is represented by an AstroPy unit object. For equality checks and printing operations, the UnitType wrapper class is used around each AstroPy unit object.
Beside physical units, PyNESTML is also able to store other types. As previously introduced, primitive types are the second type of objects which have to be managed. For this purpose, PyNESTML subsumes physical units and primitive types in a single class, namely the PredefinedTypes. In consequence, predefined types consist of type symbols for the primitive types as well as all units stored in the PredefinedUnits class. This separation has been employed in order to provide a central component for the handling of predefined as well as collected types, while the unit system in the background remains an exchangeable component. For each unit stored in the PredefinedUnits, PyNESTML creates a new type symbol and stores it in the PredefinedTypes. Moreover, all types are treated as singletons [5], i.e., the system detects and prevents redundant registration of a given type. Consequently, whenever the getType operation is called, only a reference is returned. Only buffer and non-buffer type symbols are treated as individual instances due to their different handling in the generating backend. The handling of types as singletons makes equality checks easy to achieve and reduces the overall memory consumption during the model processing [2]. The PredefinedTypes class features a set of operations used to get a type symbol or register a new one. The getType function includes a more elaborated processing. Physical unit objects which do not represent real units, e.g., in the case of ms/ms = 1, are detected and treated as being real typed. Each unit is simplified before being registered in order to avoid a redundant storage of equal units, e.g., ms == ms*ms/ms. In conclusion, this method represents the overall interface to type systems and makes extensions by new primitive as well as unit types easy to achieve, while the architecture remains modular. With the PredefinedTypes class all components required to derive new types are already available in PyNESTML, i.e., by combining basic physical units the type system is able to deal with compound units.
Types are subsequently used in the PredefinedVariables and PredefinedFunctions classes to denote the types of the elements. The PredefinedVariables class stores all predefined variables available in PyNESTML. In its current state, PyNESTML provides a set of predefined variables often required in neuroscientific models, including the global time constant t for the time past the start of the simulation, and Euler’s number e. Moreover, PyNESTML features a concept for unit variables. Consequently, it is also possible to utilize the name of a physical unit as a variable. By utilizing such a concept it is easily possible to state expressions representing new, compounded units as part of a computation. For instance, a given expression 55 * mV/nS is treated as semantically as well as syntactically correct. By handling units as predefined variables, the framework is able to apply the same set of arithmetic rules as for all other types of expressions. Compound physical units are therefore created by stating defining arithmetic expressions with basic units. All units as defined in the PredefinedTypes class are therefore also registered as predefined variables. However, in contrast to derived physical units which are automatically stored in the set of predefined types, PyNESTML does not add new unit variables to the predefined variables. Such a handling is not required since complex arithmetic combinations of units are treated as an aggregation of basic units, consequently, only variables for basic units are required. The PredefinedVariables class features methods for the retrieval of symbols for predefined variables as well as a getVariable method which can be used to detect if a variable is predefined. In the case that a handed over name does not correspond to a variable, none is returned. In this case, the client method has to take care of correct steps. In contrast to types, variable symbols located in concrete models are never added to the set of predefined ones given the fact, that these properties are local to their context and should not be visible to other models. PyNESTML reports declarations of variables with the same name as one of the predefined variables as an error, cf. Section 1.3.
Analogously to the PredefinedVariables, PyNESTML uses the PredefinedFunctions class to store all predefined functions. In its current state, PyNESTML supports 21 different mathematical and neuroscientific functions. As already introduced, each function symbol consist of a name, the type of the return value as well as a list of parameter types. All predefined functions are therefore individually initialized and stored. In order to ensure a correct type, type symbols managed by the PredefinedTypes class are retrieved and references stored. The getFunction method can then be used to request the function symbol for a specified name.
With a data structure for the representation of types as well as a basic collection of fundamental types, PyNESTML is now able to enrich the previously constructed AST by a new property, namely the concrete type of all elements. For this purpose, all AST nodes which have to be specified by a type are now, after the AST has been constructed by the lexer and parser, extended by a reference to a TypeSymbol object. Based on the type of AST node for which the type has to be derived, this step has been separated into two different phases in order to enforce a clear separation of concerns. fig-type-deriving-visitor-subsystem subsumes the type derivation subsystem.
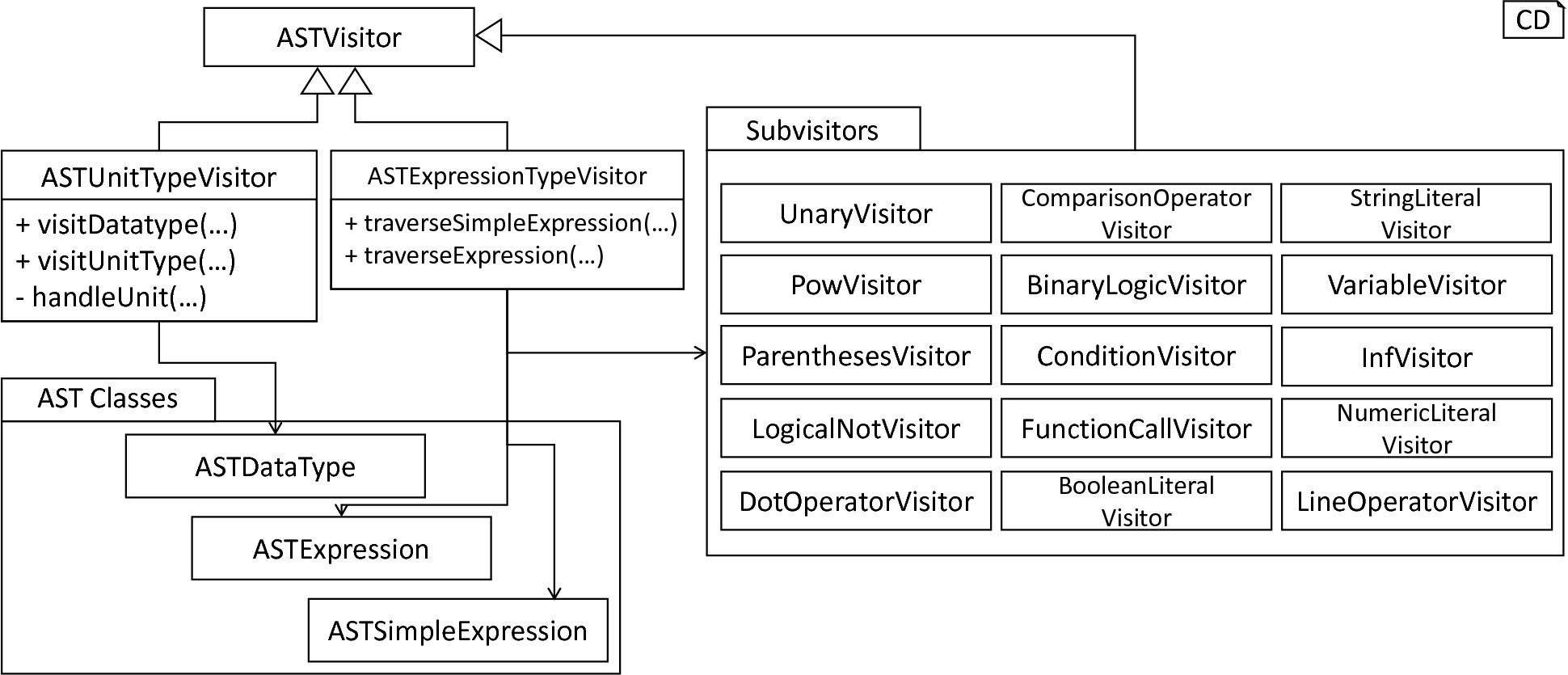
Overview of the type-deriving visitor subsystem: The ASTUnitTypeVisitor derives correct types for declarations of types as stored in ASTDataType nodes, while the ASTExpressionTypeVisitor class takes care of correct type derivation in expressions. Here, a set of assisting sub-visitors is used to derive the type symbol based on the concrete type of the expression, e.g., boolean literals or arithmetic expressions, each of which corresponding to one production of the expression grammar rule.
The simpler case is the handling of data type declarations of constants and variables defined in the model. Given the grammar for the declaration of a type where no plus or minus arithmetic operators are supported, this processing can be completely implemented in a single method. This process is therefore encapsulated in the ASTUnitTypeVisitor class which derives the concrete type symbol of a type represented by an ASTDataType node. The visitor extends the base visitor class, traverses the tree and invokes further steps whenever an ASTDataType node is detected. The visitASTDataType method checks whether a primitive or a unit type is represented by the visited node.
In the case that a primitive type has been used, a respective type symbol is simply retrieved from the predefined types collection and the reference stored. Otherwise the handling is handed over to the visitASTUnitType subroutine. This method checks how the data type has been constructed. If a simple name is used, e.g., mV, then the corresponding symbol is retrieved from the predefined types and stored. Otherwise, the method proceeds to recursively descend to the leaf nodes of the AST node, cf. fig-derivation-type-astdatatype. As defined in PyNESTML’s grammar, leaf nodes are always simple units or an integer typed value. The visitor checks which type of operation has been used to combine the leaf nodes and proceeds accordingly. For power expressions, e.g., ms2, first the type of the base is derived and consequently extended by means of the power operation. Encapsulated units, e.g., (ms*nS), are updated by setting the outer unit according to the inner one. In the case of arithmetic point operators, the visitASTUnitType method first checks whether a division or multiplication of units is performed. For the former, the left-hand side is first inspected for its type. Given the fact that data types support a numeric value on the left-hand side, e.g., 1/ms, the visitASTUnitType method checks whether it is a numeric type or not. If a numeric value is used, the method retrieves and divides it by the right-hand side. In the case of unit types, the procedure is applied recursively. Multiplication of two units is handled analogously, although here the language does not provide a concept for numeric left-hand side values.
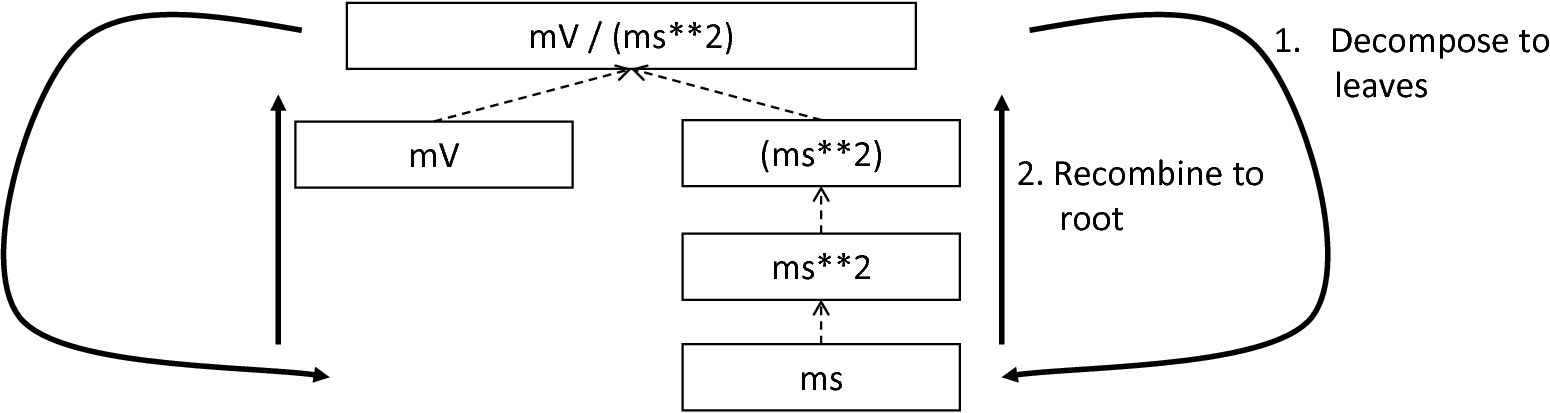
Derivation of types in ASTDataType nodes: First, the type defining expression is decomposed into its leaves. For each leaf, the corresponding type is retrieved from the PredefiendTypes class. Finally, all types are recombined according to the stated operations up to the root and the overall type is stored.
In the case of expressions, it is necessary to propagate the types of the leaves to the root of the AST node. This process requires a more sophisticated handling and traversal of the expression. The complex structure of expressions where line-, point- as well other operators can be used makes a modular structure necessary. The derivation of expression types is therefore handled by the ASTExpressionTypeVisitor, cf. fig-type-deriving-visitor-subsystem. Extending the base visitor, this class represents a traversal routine which, depending on the type of the currently processed expression, invokes an appropriate sub-visitor. The currently active sub-visitor is referenced in the real self attribute and indicates how parts of the expressions have to be handled. It consequently checks the type of an element in the expression, e.g., whether it is a boolean literal or an arithmetic combination of two ubexpressions, and sets the real self visitor according to this element. In its current state, PyNESTML supports 15 different sub-visitors, amongst others the unary visitor used to update the expression prefixed with a unary plus, minus or tilde, the power visitor for the calculation of the type of an exponent expression, the parentheses visitor for the type derivation of encapsulated expressions, the logical not visitor for the handling of negated logical expressions, the dot and line operators for handling of arithmetical expressions, the comparison visitor for handling of comparisons and the binary logic visitor for the handling of logical and and or.
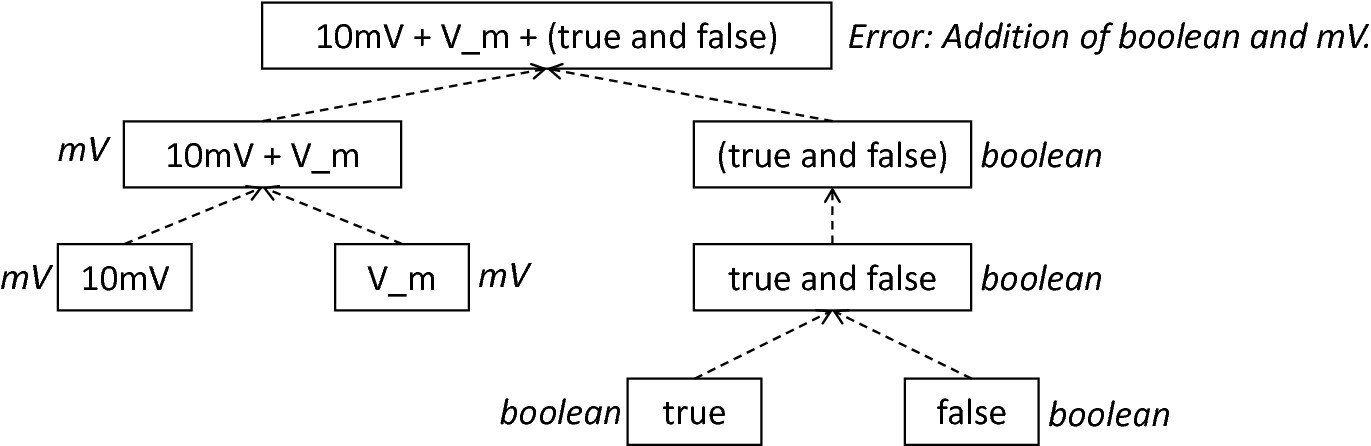
Derivation of types in ASTExpression nodes: Analogously to ASTDataTypes nodes, an expression is first decomposed into its leaf nodes. Subsequently, the corresponding variable symbol is resolved, and its type symbol retrieved. Type symbols are combined according to the operations used to construct the expressions. In the case of errors, e.g., a combination of boolean and numeric types, an error message is propagated to the root.
The use case demonstrated in fig-derivation-type-astexpression exemplifies the overall process: Given the expression 10mV + V_m + (true and false) with the variable V_m of unit type millivolt, first, the ASTExpressionTypeVisitor descends to the leaf level, namely the nodes 10mV, V_m, true and false. For 10mV, the numeric literal visitor is activated which checks whether the expression utilizes a physical unit or not. In the case that a unit is used, the visitor resolves the name of the unit and sets the retrieved type symbol to the type of the node. If no unit is used, the visitor checks whether a real or integer literal is present and retrieves the corresponding type symbol from the predefined types collection. Analogously, the V_m variable is inspected by the variable visitor, and the variable name is resolved to the corresponding variable symbol. Each variable symbol stores a reference to its type symbol. Consequently, this type symbol is retrieved and used as the type of the literal in the expression, e.g., here the type mV. For the boolean true and false, the boolean visitor is used. It simply inspects whether a boolean literal has been used and sets the type of the corresponding expression to the boolean type symbol as stored in the predefined types collection. Having the types of all leaf nodes, the visitor starts to ascend. The expression 10mV + V_m is a line operator combination of two values, thus the line operator visitor is activated. The arithmetic plus operator should only be applicable for numeric values and variables representing such. The left- as well as the right-hand side of the plus operator refer to unit values and have the same type, hence the overall type of the expression is set to mV. In the case of true and false, the and operator can only be used to combine boolean values, which applies in the given case, thus the binary logic visitor is used which updates the type of the combined expression to boolean. The boolean expression has been encapsulated in parentheses which makes an invocation of the parentheses visitor necessary. This visitor simply retrieves the type of the inner part of the encapsulated expression and updates the type of the overall expression accordingly, e.g., in our case to boolean. Finally, the root of the expression is reached, namely the arithmetic combination of the expressions 10mV+V_m of type mV and (true and false) of type boolean. Obviously, such an expression is not correctly typed. The line operator visitor detects that incompatible types have been used and sets the type of the expression to an error value. In order to enable PyNESTML to store either a correct type or an error message, the Either class is used. This class stores either a reference to a type symbol or a string containing an error message. By storing an object of this type instead of an undefined unit, PyNESTML is able to derive and interact with errors and propagate the messages to the root of the expression. All detected errors are hereby reported as being of semantical nature, cf. Section 1.3. In the given example, the overall type of the expression is an object of the Either class with an error message stating that an arithmetic combination of numeric and non-numeric values is not possible. Together with all remaining visitors, this system is able to derive the type of arbitrary expressions by propagating and combining leaf-node types to the root. Here we see exactly why the physical unit system AstroPy with its support for arithmetic operators was used: Given the expression 10mV * 2ms, PyNESTML should be able to combine the underlying units to a new one, and the overall type of the expression should be set to mV*ms. Such a processing is vehemently simplified if the framework’s underlying physical units library supports arithmetic operations on units for the creation of new ones.
This section introduced the type system and showed how PyNESTML stores and processes declarations and their respective types. Here, we first implemented data structures to store details of defined elements in the model. Subsequently, we demonstrated how a set of predefined elements is initialized by the predefined subsystem. Finally, these elements were used to derive the type of all expressions located in the model by means of the ASTDataTypeVisitor and ASTExpressionTypeVisitor classes. We will come back to types in the next section where correct typing of expressions as well as other semantical properties are introduced.
Section 1.3: Semantical Checks
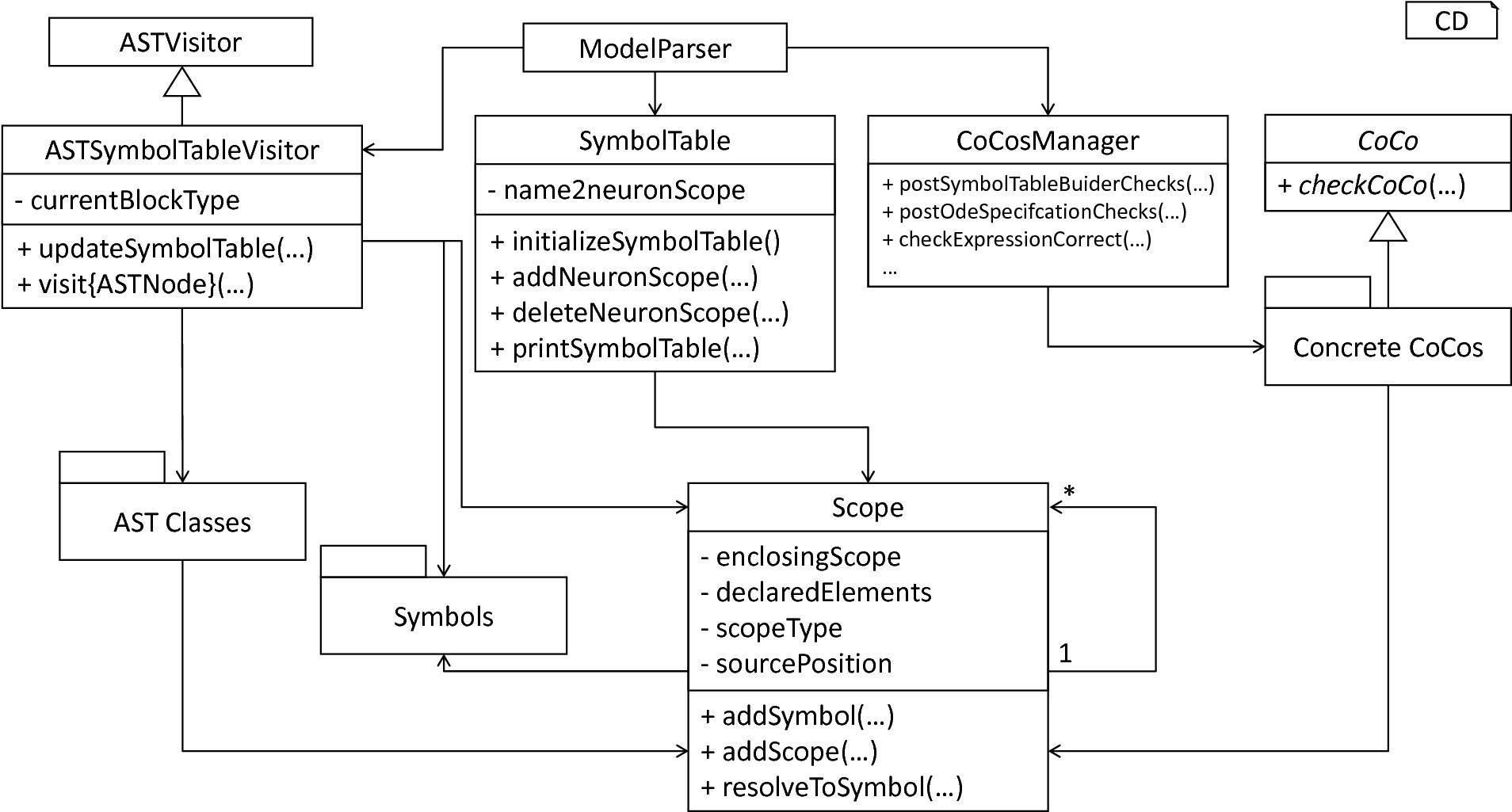
Overview of semantical checks: The orchestrating ModelParser class utilizes the ASTSymbolTableVisitor to construct a model’s hierarchy of Scope objects. Each scope is populated by Symbol objects corresponding to elements defined in the respective model. In order to manage all processed neurons in a central unit, the SymbolTable class is used. Finally, the ModelParser calls all model-analyzing routines of the CoCosManager class and checks the model for semantical correctness. The CoCosManager class utilizes different CoCos to check several properties of the given model.
After the AST of a given model has been constructed, comments have been collected and the type of all elements derived, the model-processing frontend proceeds to the last step, namely the checking of the semantical correctness of a handed over textual model. For this purpose, we first implement data structures for the storage of a neuron’s concrete context, namely the SymbolTable and Scopes classes. In order to fill these components with context information, a collecting process implemented in the ASTSymbolTableVisitor is used. After the context of a model has been established, it remains to check for correct semantics. This task is delegated to the CoCosManager, a component which manages a collection of context conditions. fig-semantical-checks illustrates which components have been implemented to store, collect and check semantical details of a model.
The SymbolTable class represents a container which maps neuron names to their respective global scope. The scope of an AST object is hereby an element of the Scope class which stores a reference to its parent scope, leading to a tree-like structure of the scope layering. Utilizing such a structure accelerates the resolving of symbols and eases the working with the context of a model. All elements contained in a scope are hereby stored in a list. Each element is either a Symbol or a sub-Scope. The final two attributes of the Scope class store details regarding the type of the scope and the source location. The former is used to enable an easy to conduct filtering of scopes. For this purpose the enumeration type ScopeType is implemented. Each scope is marked as being global, update or function. All elements defined outside the update and function block are stored in a neuron’s top-level scope, while the update and function block can be used to open new sub-scopes. The source location attribute contains the position enclosed by the scope. Storing this detail is beneficial especially in the case of error reports and troubleshooting of textual models.
Besides data retrieval and manipulation operations, the Scope class features several aiding methods: The getSymbolsInThisScope method can be used to retrieve all symbols in the current scope, while getSymbolsInCompleteScope also takes all shadowed symbols in ancestor scopes into account. The getScopes operation can be used to return all sub-scope objects of the current scope. In order to retrieve the top scope of a neuron, the getGlobalScope method can be used. Finally, the resolve methods are provided. The Scope class implements two different operations and supports a more precise retrieval of information. The resolveToAllScopes method can be used to retrieve all scopes in which a symbol with the handed over name and symbol kind has been declared. The resolveToAllSymbols returns the corresponding symbols. These methods can be used whenever shadowing of variables should be handled and all specified symbols returned. The respective single instance methods resolveToScope and resolveToSymbol can be used to return the first defined instance of a symbol specified by the parameters. Starting from the current scope, these methods first check if the specified symbol is contained in the scope. If such a symbol is found, it is simply returned, otherwise, the same operation is performed on the parent scope. In conclusion, this method can be used to check if a used element has been declared in the spanned scope of the current block. fig-symbol-resolution-process illustrates the resolution process.
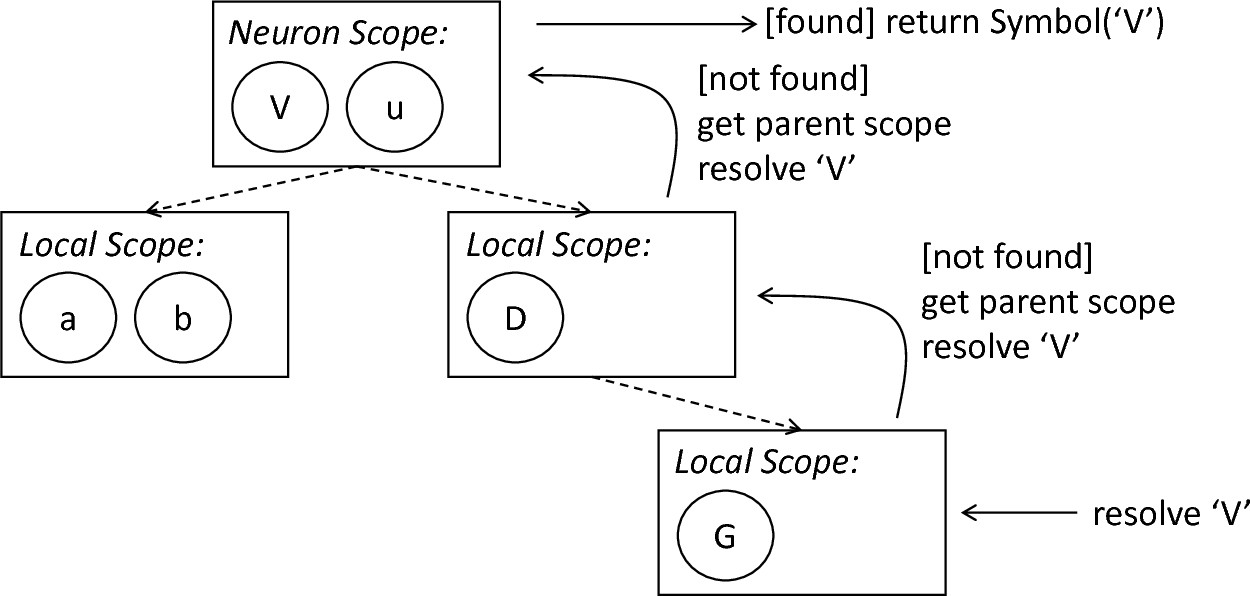
The symbol resolution process: The request to return a Symbol object corresponding to a given name is received by the nested scope. The scope is checked, and if no symbol with the corresponding name and type is found, a recursive call to the resolution process on the nesting scope is performed. If a symbol has been found, it is returned, otherwise an error is indicated by returning none.
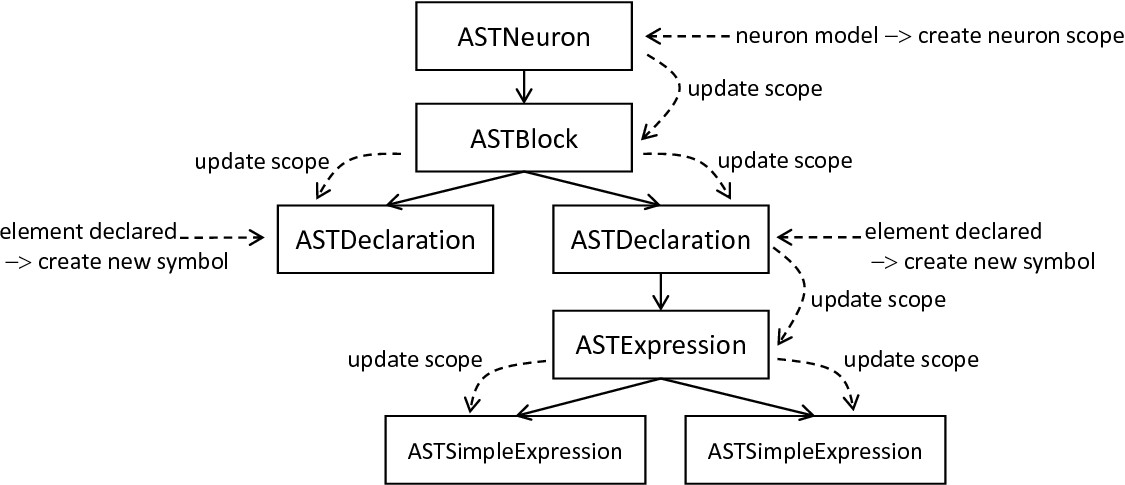
AST context-collecting and updating process: Starting at the root, i.e., the ASTModel object, the ASTSymbolTableVisitor creates a neuron-specific scope and descends into the AST. For each node, the routine checks if a child node is stored, and updates its scope according to the current one. Found declarations are used to create new symbols which are consequently stored in the parent’s scope.
The SymbolTable class represents a data structure which has to be instantiated and filled with the context information of concrete models. PyNESTML delegates this task to the ASTSymbolTableVisitor class, a component which implements all required steps to fill the symbol table with life. The overall interface of this class consists of the visit method which expects the concrete AST whose context shall be analyzed and updated accordingly. Based on the visited node, this operation invokes one of the following processings: In the case that an ASTModel node is visited, a new neuron wide scope is created. Moreover, in order to fill the scope with predefined properties which are always available in the context, references to elements of the predefined subsystem are stored. This step ensures that the resolution process of predefined and model-specific variables becomes transparent and accessible over the neuron’s scope. It is therefore not required to access individual collections of the predefiend subsystem to get the respective elements. Instead, all symbols required by a model are stored in its respective top-level scope and the PredefinedTypes collection. Moreover, given the structure of the visitor, it is not directly possible to indicate certain details to processed child nodes, e.g., the top level scope of the currently handled neuron or which type of block [3] is processed. While the former is solved by a top-down update process as illustrated in fig-ast-context-collecting-updating, i.e., before a node is visited, its scope is updated to the parent’s scope, the latter requires storage of additional details. Consequently, the type of the currently processed block is stored and represented as a value of the BlockType enumeration. Whenever a block of statements is entered, the type of the block is simply stored and removed after the block has been left. Newly created symbols inside the block check this value and derive the information in which type of block they were created. Such a processing is required in order to determine the ScopeType of each created (sub-) scope as well as the BlockType of created symbols [4].
The creation of new symbols and scopes is only required in a limited set of cases. Most often, only the scope reference of a handled element has to be updated. As shown in fig-ast-context-collecting-updating, this step is done in a reversed order: The neuron’s root AST node stores a reference to its scope, and subsequently sets the scope of its child nodes to the parent scope. In the case that a block is detected which has to span its own local scope, i.e., an update or function block, a new Scope object is created and stored in the parent scope. This new object is then set as the scope of the nested block and the process is continued recursively. Thus, whenever a scope-spanning block is detected, a new scope is stored in the parent scope, and used in the following as the current scope. The individual visit methods of the ASTSymbolTableVisitor therefore first update the scopes of their child nodes before a further traversal is invoked. Constants and variables declared in the model require an additional step. Here it is necessary to create a new Symbol object representing the declared element. Concrete information regarding the specifications of the symbol is stored in the current AST object, while the TypeSymbol can be easily retrieved by inspecting the ASTDataType child node. Here we see exactly why a preprocessing by the ASTDataTypeVisitor, cf. Section 1.2, is required. Having an AST where all nodes have been provided with their respective TypeSymbols, the ASTSymbolTableVisitor can now easily retrieve this information and use it in VariableSymbols. All required details are therefore simply retrieved from the corresponding element, and a new VariableSymbol is created and stored in the current scope. In the case of user-defined functions, this process is performed analogously, although here a FunctionSymbol is created. The ASTSymbolTableVisitor executes this process for the whole AST and populates the symbol table with scope details. As a side effect, the scopes of all AST objects are updated correctly and can now be used for further checks.
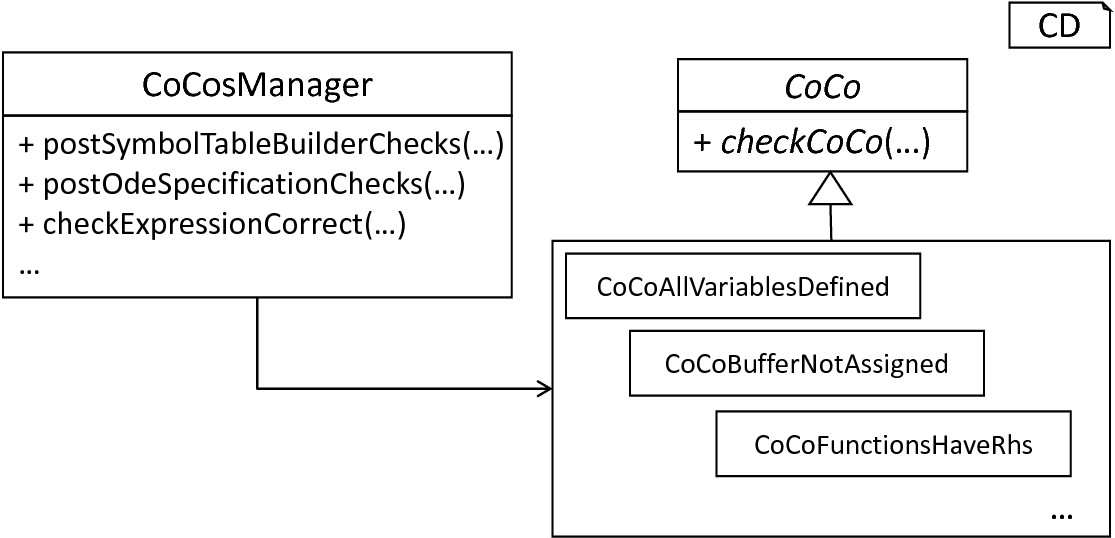
The CoCosManager and context conditions: The CoCosManager* class represents a central unit which executes all required checks on the handed over model. Each checked feature of the model is encapsulated by a single class which inherits the abstract CoCo class.
After a neuron’s scopes have been adjusted, the final step of the model-processing frontend is invoked, namely the checking of semantical correctness. This steps is performed by means of so-called context conditions. Here a modular structure has been employed. PyNESTML implements each context condition as an individual class with the prefix CoCo and a meaningful name, e.g., CocoVariableOncePerScope. In order to subsume the overall checking routine in a single component, the CoCosManger class has been implemented, cf. fig-cocosmanager-context-conditions. Its postSymbolTableBuilderChecks method can be used to check all context conditions after the symbol table has been constructed, while the postOdeSpecificationChecks method checks if all ODE declarations have been correctly stated in the raw AST.
Given the fact that context conditions have the commonality of checking the context of a neuron model, PyNESTML implements the abstract CoCo super class. All concrete context conditions therefore have to implement the checkCoCo operation which expects a single AST for checking. Concrete context condition classes describe in a self-contained manner which definitions lead to an erroneous model. Consequently, here a black list concept is applied: For models which feature certain characteristics it is not possible to generate correct results. These characteristics should be reported. In its current state, PyNESTML features 25 different context conditions which ensure the overall correct structure of a given model. The following composition outlines the implemented conditions:
CoCoAllVariablesDefined: Checks whether all used variables are previously defined and no recursive declaration is stated.
CoCoBufferNotAssigned: Checks that no values are assigned to (read-only) buffers.
CoCoConvolveCondCorrectlyBuilt: Checks that each convolve function-call is provided with correct arguments, namely a kernel and a buffer.
CoCoCorrectNumeratorOfUnit: Checks that the numerator of a unit type is equal to one, e.g., 1/mV.
CoCoCorrectOrderInEquation: Checks whether a differential equation has been stated for a non-derivative, e.g., V_m = V_m’ instead of V_m’ = V_m’.
CoCoCurrentBuffersNotSpecified: Checks that current buffers are not specified with the keyword inhibitory or excitatory. Only spike buffers can be further specified.
CoCoEachBlockUniqueAndDefined: Checks that mandatory update, input and output blocks are defined exactly once, and all remaining types of blocks are defined at most once.
CoCoEquationsOnlyForInitValues: Checks that equations are only defined for variables stated in the initial values block.
CoCoFunctionCallsConsistent: Checks that all function calls are consistent, i.e., that the called function exists and the arguments are of the correct type and amount.
CoCoFunctionHasRhs: Checks that all attributes marked by the function keyword have a right-hand side expression.
CoCoFunctionMaxOneLhs: Checks that multi-declarations marked as functions do not occur, e.g., function V_m,V_n mV = V_i + 42mV. Several aliases to the same value are redundant.
CoCoFunctionUnique: Checks that all functions are unique, thus user-defined functions do not redeclare predefined ones.
CoCoIllegalExpression: Checks that all expressions are typed according to the left-hand side variable, or are at least castable to each other.
CoCoInvariantIsBoolean: Checks that the type of all given invariants is boolean.
CoCoModelNameUnique: Checks that no name collisions of neurons occur. Here, only the names in the same artifact are checked.
CoCoNoNestNameSpaceCollision: Checks that user-defined functions and attributes do not collide with the namespace of the target simulator platform NEST.
CoCoNoKernelsExceptInConvolve: Checks that variables marked as kernels are only used in the convolve function call.
CoCoNoTwoNeuronsInSetOfCompilationUnits: Checks across several compilation units (and therefore artifacts) whether neurons are redeclared. Only invoked when several artifacts are given.
CoCoOnlySpikeBufferWithDatatypes: Checks that only spike buffers have been provided with a data type. Current buffers are always of type pA.
CoCoParametersAssignedOnlyInParameterBlock: Checks that values are assigned to parameters only in the parameter block.
CoCoConvolveHasCorrectParameter: Checks that convolve calls are not provided with complex expressions, but only variables.
CoCoTypeOfBufferUnique: Checks that no keyword is stated twice in an input buffer declaration, e.g., inhibitory inhibitory spike.
CoCoUserDeclaredFunctionCorrectlyDefined: Checks that user-defined functions are correctly defined, i.e., only parameters of the function are used, and the return type is correctly stated.
CoCoVariableOncePerScope: Checks that each variable is defined at most once per scope, i.e., no variable is redefined.
CoCoVectorVariableInNonVectorDeclaration: Checks that vector and scalar variables are not combined, e.g. V + V_vec where V is scalar and V_vec a vector.
In the following we exemplify the underlying process on two concrete context conditions, namely CoCoFunctionUnique and CoCoIllegalExpression. The former is used to check whether an existing function has been redefined in a given model. With the previously done work, this property can be easily implemented: Given the fact that in the basic context of the language no functions are defined twice, the checkCoco method of the CoCoFunctionUnique class simply retrieves all user-defined functions, resolves them to the corresponding FunctionSymbols as constructed by the ASTSymbolTableVisitor and checks pairwise whether two functions with the same name exist. In order to preserve a simple structure of PyNESTML, function overloading is not included as an applicable concept. Thus, only collisions of function names have to be detected. If a collision has been detected, an error message is printed and stored by means of the further on introduced Logger class, cf. Section 2: Assisting Classes. With the names of all defined FunctionSymbols (and analogously VariableSymbols) it is easily possible to check whether a redeclaration occurred. Moreover, the stored reference to the corresponding AST node can be used to print the position at which the model is not correct, making troubleshooting possible. fig-simple-complex-coco illustrates the CoCoFunctionUnique class.
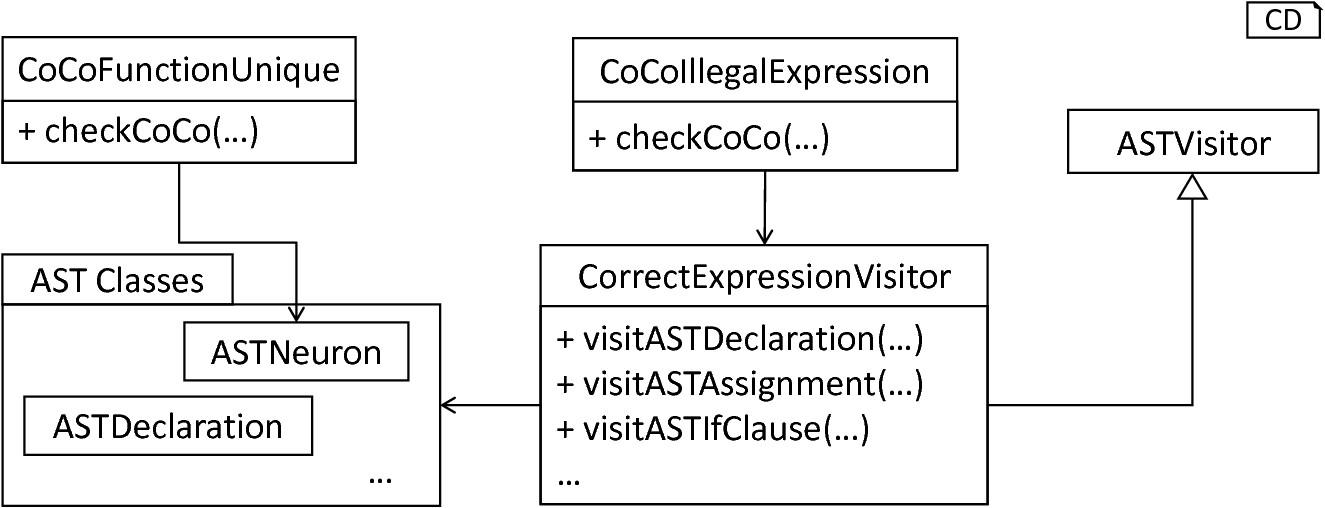
Simple and complex context conditions: Simple context conditions such as CoCoFunctionUnique can be implemented in a single function, while more complex conditions such as CoCoIllegalExpression also utilize additional classes and visitors. Both types of context conditions work on the handed over AST.
The second exemplified context condition CoCoIllegalExpression checks whether the expected data type of elements and their corresponding expressions have the same value. With the previously derived TypeSymbols of all AST nodes and the instantiated symbol table, here a simple process becomes sufficient for an in-depth checking of correctly typed models. To check correct typing of all required components, the assisting CorrectExpressionVisitor is implemented, cf. fig-simple-complex-coco. This visitor implements the basic ASTVisitor and overrides the visit method for nodes whose types have to be checked. In the case of declarations and assignments, it resolves the variable symbol of the left-hand side variable and retrieves the corresponding type symbol. For the right-hand side expression, the getType of the (simple) expression object is called. Finally, the equals method is used to check whether both types are equivalent. Here, an additional check has been implemented: Given the fact that most simulators disregard physical units, but work in terms of integers and doubles, it can be beneficial to allow certain implicit castings. For this purpose the isCastableTo method of the further on introduced ASTUtils class is used. This function can be invoked to check whether one given type can be converted to a different one. For instance, this method returns true whenever a physical unit TypeSymbol and a real TypeSymbol are handed over, since each unit typed value is implicitly regard as being of type real. Analogously, real and integer can be casted to each other, although here the fraction of a value might be lost. An implicit cast is always reported with a warning to inform the user of potential errors in the simulation. If an implicit cast is not possible, e.g., casting of a string to an integer, an error message is printed informing the user of a broken context. Warnings, therefore, state that a given model could possibly contain unintended behavior, while errors indicate semantical incorrectness.
The second type of checks as implemented in the CoCoIllegalExpression is a comparison of magnitudes: Values which utilize the same physical unit but differ in magnitude have to be regarded as being combinable. It should, therefore, be possible to add up 1mV and 1V, although the underlying combination of a prefix and unit is not equal. This task is handed over to the differsInMagnitude method of the ASTUtils class, cf. Section 2: Assisting Classes. This method simply checks whether the physical units without the prefixes are equal and returns the corresponding truth value. The remaining context conditions are implemented in an analogous manner: If complex checks on all nodes of the AST are required, a new visitor is implemented. In more simple cases a single function is sufficient. Errors and warnings are reported by means of the Logger class, cf. Section 2: Assisting Classes.
In this section, we introduced how context related details of a model can be stored and checked. For this purpose, we first implemented the SymbolTable class which stores references to all processed neuron scopes. The Scope class has hereby been used to represent scope spanning blocks which are then populated by sub-scopes and symbols. In order to instantiate a model’s scope hierarchy, the ASTSymbolTableVisitor was introduced. Finally, the constructed symbol table was used to check the context of the handed over model for correctness. Here, the orchestrating CoCosManager class delegated all required checks to individual context condition classes, with the result being an AST which has been tested for semantical correctness.